Timescale Cloud: Performance, Scale, Enterprise
Self-hosted products
MST
Timescale Cloud charges are based on the amount of storage you use. You don't pay for fixed storage size, and you don't need to worry about scaling disk size as your data grows—we handle it all for you. To reduce your data costs further, combine hypercore, a data retention policy, and tiered storage.
You use Timescale Console![]() to resize the compute (CPU/RAM) resources available to your
Timescale Cloud services at any time, with a short downtime.
to resize the compute (CPU/RAM) resources available to your
Timescale Cloud services at any time, with a short downtime.
You can change the CPU and memory allocation for your Timescale Cloud service at any time with minimal downtime, usually less than a minute. The new resources become available as soon as the service restarts. You can change the CPU and memory allocation up or down, as frequently as required.
There is momentary downtime while the new compute settings are applied. In most cases, this is less than a minute. However, Before making changes to your service, best practice is to enable HA replication on the service. When you resize a service with HA enabled, Timescale Cloud:
- Resizes the replica.
- Waits for the replica to catch up.
- Performs a switchover to the resized replica.
- Restarts the primary.
HA reduce downtime in the case of resizes or maintenance window restarts, from a minute or so to a couple of seconds.
When you change resource settings, the current and new charges are displayed immediately so that you can verify how the changes impact your costs.

Warning
Because compute changes require an interruption to your Timescale Cloud services, plan accordingly so that the settings are applied during an appropriate service window.
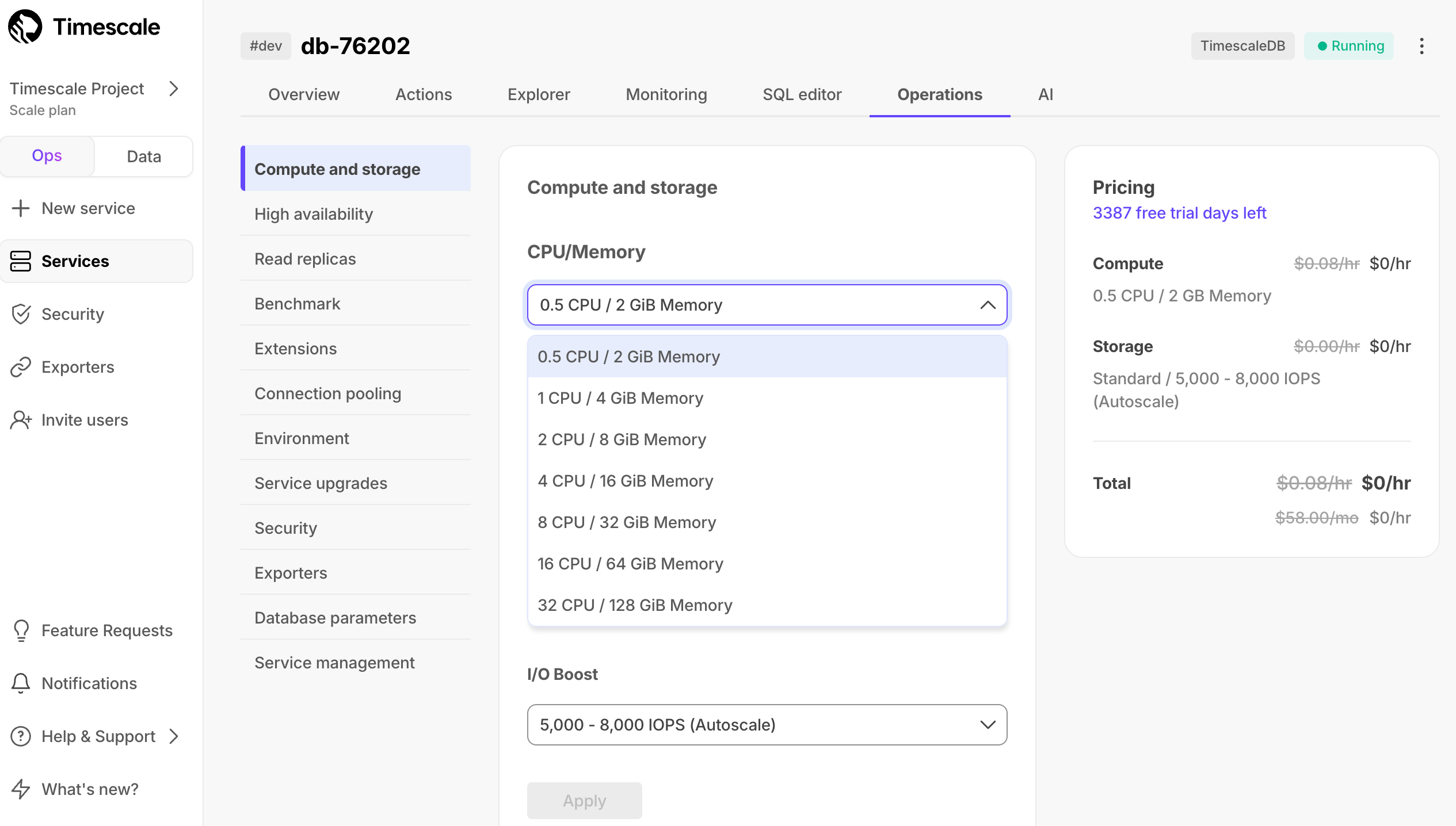
- In Timescale Console
 , choose the service to modify.
, choose the service to modify. - Click
Operations, then clickCompute. - Select the new
CPU / Memoryallocation. You see the allocation and costs in the comparison chart - Click
Apply. Your service goes down briefly while the changes are applied.
If you run intensive queries on your Timescale Cloud services, you might encounter out of memory (OOM) errors. This occurs if your query consumes more memory than is available.
When this happens, an OOM killer process shuts down PostgreSQL processes using
SIGKILL commands until the memory usage falls below the upper limit. Because
this kills the entire server process, it usually requires a restart.
To prevent service disruption caused by OOM errors, Timescale Cloud attempts to shut down only the query that caused the problem. This means that the problematic query does not run, but that your Timescale Cloud service continues to operate normally.
If the normal OOM killer is triggered, the error log looks like this:
2021-09-09 18:15:08 UTC [560567]:TimescaleDB: LOG: server process (PID 2351983) was terminated by signal 9: KilledWait for the Timescale Cloud service to come back online before reconnecting.
Timescale Cloud shuts the client connection only
If Timescale Cloud successfully guards the service against the OOM killer, it shuts down only the client connection that was using too much memory. This prevents the entire Timescale Cloud service from shutting down, so you can reconnect immediately. The error log looks like this:
2022-02-03 17:12:04 UTC [2253150]:TimescaleDB: tsdbadmin@tsdb,app=psql [53200] ERROR: out of memory
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.