For Timescale Cloud Service with very low tolerance for downtime, Timescale Cloud offers High Availability (HA) replicas. HA replicas significantly reduce the risk of downtime and data loss due to system failure, and enable services to avoid downtime during routine maintenance.
This page shows you how to choose the best high availability option for your Timescale Cloud Service.
HA replicas are exact, up-to-date copies of your database hosted in multiple AWS availability zones (AZ) within the same region as your primary node. They automatically take over operations if the original primary data node becomes unavailable. The primary node streams its write-ahead log (WAL) to the replicas to minimize the chances of data loss during failover.
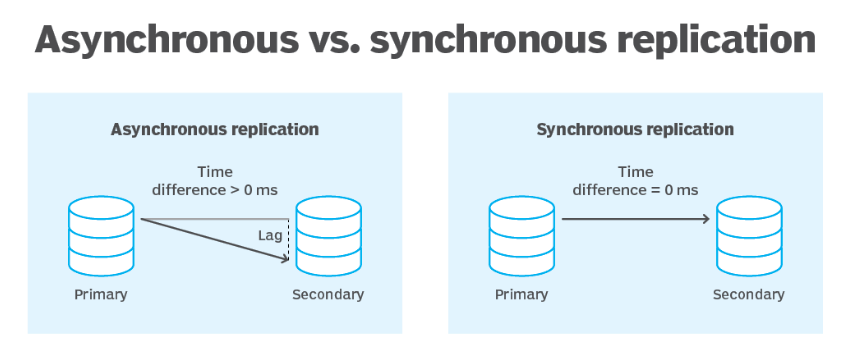
HA replicas can be synchronous and asynchronous.
- Synchronous: the primary commits its next write once the replica confirms that the previous write is complete. There is no lag between the primary and the replica. They are in the same state at all times. This is preferable if you need the highest level of data integrity. However, this affects the primary ingestion time.
- Asynchronous: the primary commits its next write without the confirmation of the previous write completion. The asynchronous HA replicas often have a lag, in both time and data, compared to the primary. This is preferable if you need the shortest primary ingest time.
HA replicas have separate unique addresses that you can use to serve read-only requests in parallel to your primary data node. When your primary data node fails, Timescale Cloud automatically fails over to an HA replica within 30 seconds. During failover, the read-only address is unavailable while Timescale Cloud automatically creates a new HA replica. The time to make this replica depends on several factors, including the size of your data.
Operations such as upgrading your Timescale Cloud Service to a new major or minor version may necessitate a service restart. Restarts are run during the maintenance window. To avoid any downtime, each data node is updated in turn. That is, while the primary data node is updated, a replica is promoted to primary. After the primary is updated and online, the same maintenance is performed on the HA replicas.
To ensure that all Timescale Cloud Services have minimum downtime and data loss in the most common failure scenarios and during maintenance, rapid recovery is enabled by default for all services.
The following HA configurations are available in Timescale Cloud:
Non-production: no replica, best for developer environments.
High availability: a single async replica in a different AWS availability zone from your primary. Provides high availability with cost efficiency. Best for production apps.
Highest availability: two replicas in different AWS availability zones from your primary. Available replication modes are:
- High performance - two async replicas. Provides the highest level of availability with two AZs and the ability to query the HA system. Best for absolutely critical apps.
- High data integrity - one sync replica and one async replica. The sync replica is identical to the primary at all times. Best for apps that can tolerate no data loss.
The following table summarizes the differences between these HA configurations:
| High availability (1 async) | High performance (2 async) | High data integrity (1 sync + 1 async) | |
|---|---|---|---|
| Write flow | The primary streams its WAL to the async replica, which may have a slight lag compared to the primary, providing 99.9% uptime SLA. | The primary streams its writes to both async replicas, providing 99.9+% uptime SLA. | The primary streams its writes to the sync and async replicas. The async replica is never ahead of the sync one. |
| Additional read replica | Recommended. Reads from the HA replica may cause availability and lag issues. | Not needed. You can still read from the HA replica even if one of them is down. Configure an additional read replica only if your read use case is significantly different from your write use case. | Highly recommended. If you run heavy queries on a sync replica, it may fall behind the primary. Specifically, if it takes too long for the replica to confirm a transaction, the next transaction is canceled. |
| Choosing the replica to read from manually | Not applicable. | Not available. Queries are load-balanced against all available HA replicas. | Not available. Queries are load-balanced against all available HA replicas. |
| Sync replication | Only async replicas are supported in this configuration. | Only async replicas are supported in this configuration. | Supported. |
| Failover flow |
|
|
|
| Cost composition | Primary + async (2x) | Primary + 2 async (3x) | Primary + 1 async + 1 sync (3x) |
| Tier | Performance, Scale, and Enterprise | Scale and Enterprise | Scale and Enterprise |
The High and Highest HA strategies are available with the Scale and the Enterprise pricing plans.
To enable HA for a Timescale Cloud Service:
- In Timescale Console, select the service to enable replication for.
- Click
Operations, then selectHigh availability. - Choose your replication strategy, then click
Change configuration.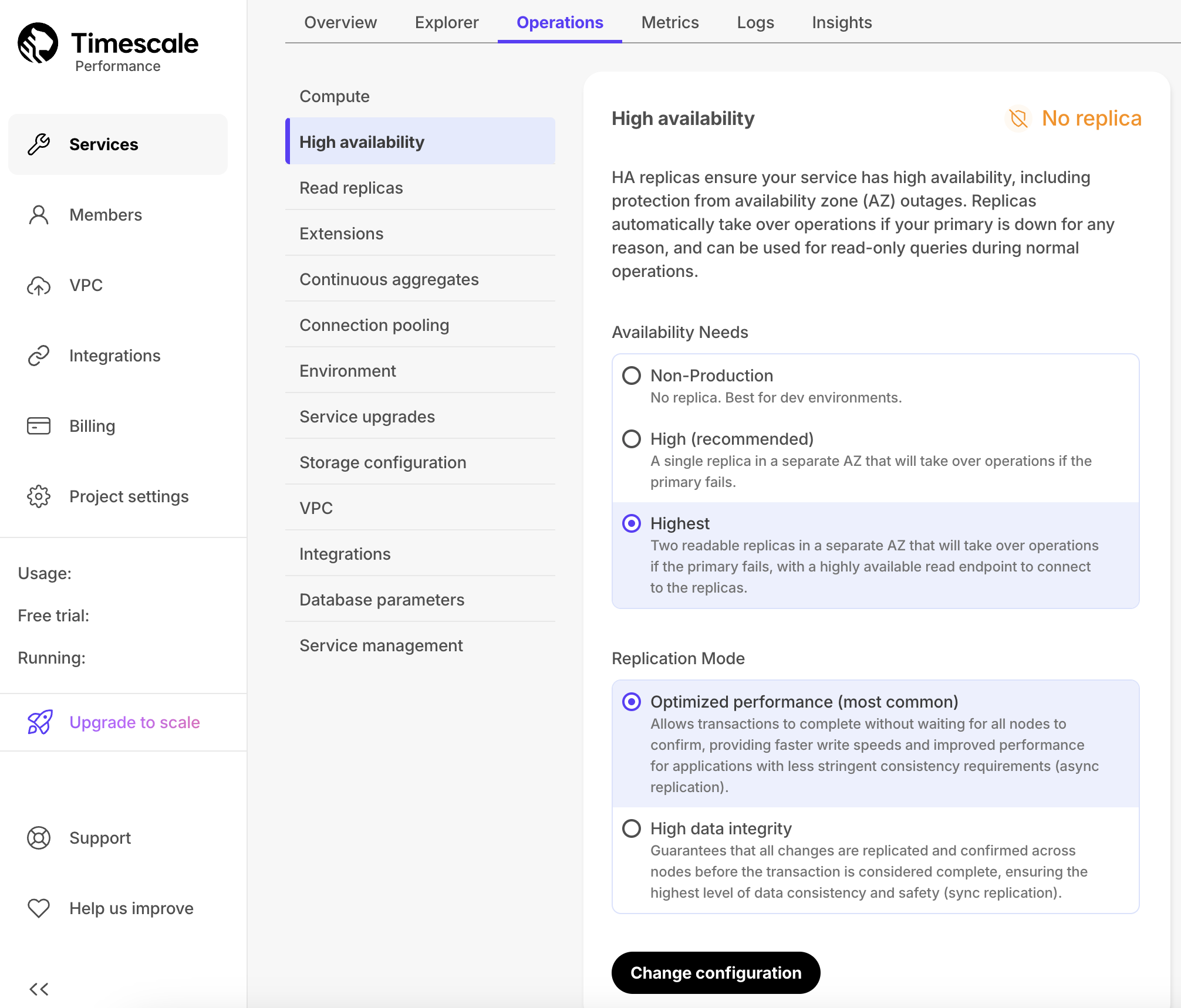
- In
Change high availability configuration, clickChange config.
To change your HA replica strategy, click Change configuration, choose a strategy and click Change configuration.
To download the connection information for the HA replica, either click the link next to the replica
Active configuration, or find the information in the Overview tab for this service.
To test the failover mechanism, you can trigger a switchover. A switchover is a safe operation that attempts a failover, and throws an error if the replica or primary is not in a state to safely switch.
Connect to your primary node as
tsdbadminor another user that is part of thetsdbownergroup.
Note
You can also connect to the HA replica and check its node using this procedure.
At the
psqlprompt, connect to thepostgresdatabase:\c postgresYou should see
postgres=>prompt.Check if your node is currently in recovery:
select pg_is_in_recovery();Check which node is currently your primary:
select * from pg_stat_replication;Note the
application_name. This is your service ID followed by the node. The important part is the-an-0or-an-1.Schedule a switchover:
CALL tscloud.cluster_switchover();By default, the switchover occurs in 30 secs. You can change the time by passing an interval, like this:
CALL tscloud.cluster_switchover('15 seconds'::INTERVAL);Wait for the switchover to occur, then check which node is your primary:
SELECT * FROM pg_stat_replication;You should see a notice that your connection has been reset, like this:
FATAL: terminating connection due to administrator commandSSL connection has been closed unexpectedlyThe connection to the server was lost. Attempting reset: Succeeded.Check the
application_name. If your primary was-an-1before, it should now be-an-0. If it was-an-0, it should now be-an-1.
Keywords
Found an issue on this page?Report an issue or Edit this page in GitHub.