All the latest features and updates to Timescale products.
October 18, 2024After creating a service, users can now create a hypertable directly in Timescale Console by first creating a table, then converting it into a hypertable. This is possible using the in-console SQL editor. All standard hypertable configuration options are supported, along with any customization of the underlying table schema.
The newest version of Data Mode Notebooks is now waaaay faster. Why? We've incorporated the newly developed v3 of our query engine that currently powers Timescale Console's SQL Editor. Check out the difference in query response times.
October 10, 2024Last year, we began developing a solution for low-downtime migration from PostgreSQL and TimescaleDB. Since then, this solution has evolved significantly, featuring enhanced functionality, improved reliability, and performance optimizations. We're now proud to announce that live migration is production-ready with the release of version 1.0.
Many of our customers have successfully migrated databases to Timescale using live migration, with some databases as large as a few terabytes in size.
As part of the service creation flow, we offer the following:
- Connect to services from different sources
- Import and migrate data from various sources
- Create hypertables
Previously, these actions were only visible during the service creation process and couldn't be accessed later. Now, these actions are persisted within the service, allowing users to leverage them on-demand whenever they're ready to perform these tasks.
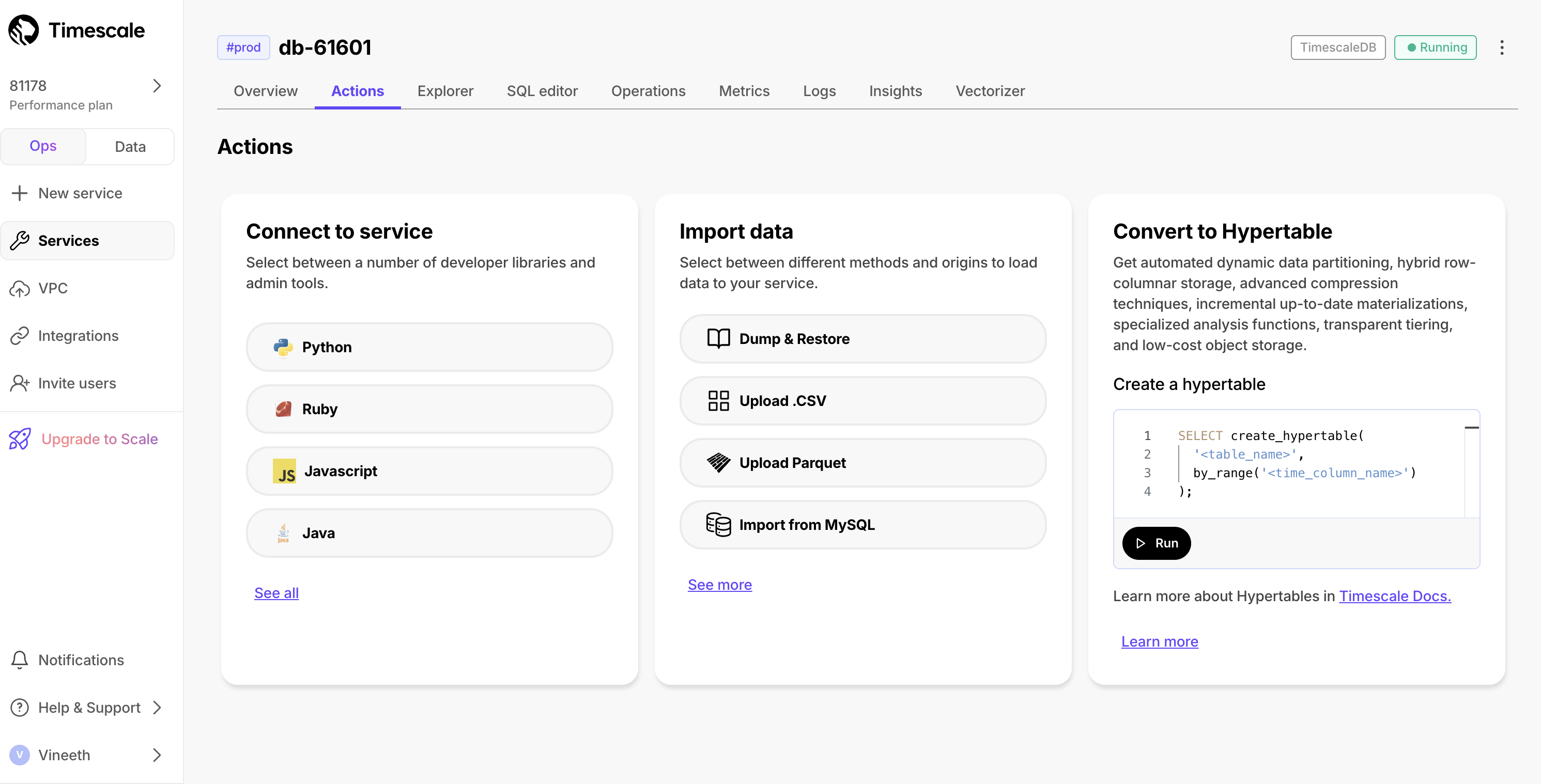
We've noticed users struggling to convert their MySQL schema and data into their Timescale Cloud services. This was due to the semantic differences between MySQL and PostgreSQL. To simplify this process, we now offer easy-to-follow instructions to import data from MySQL to Timescale Cloud. This feature is available as part of the data import wizard, under the Import from MySQL option.
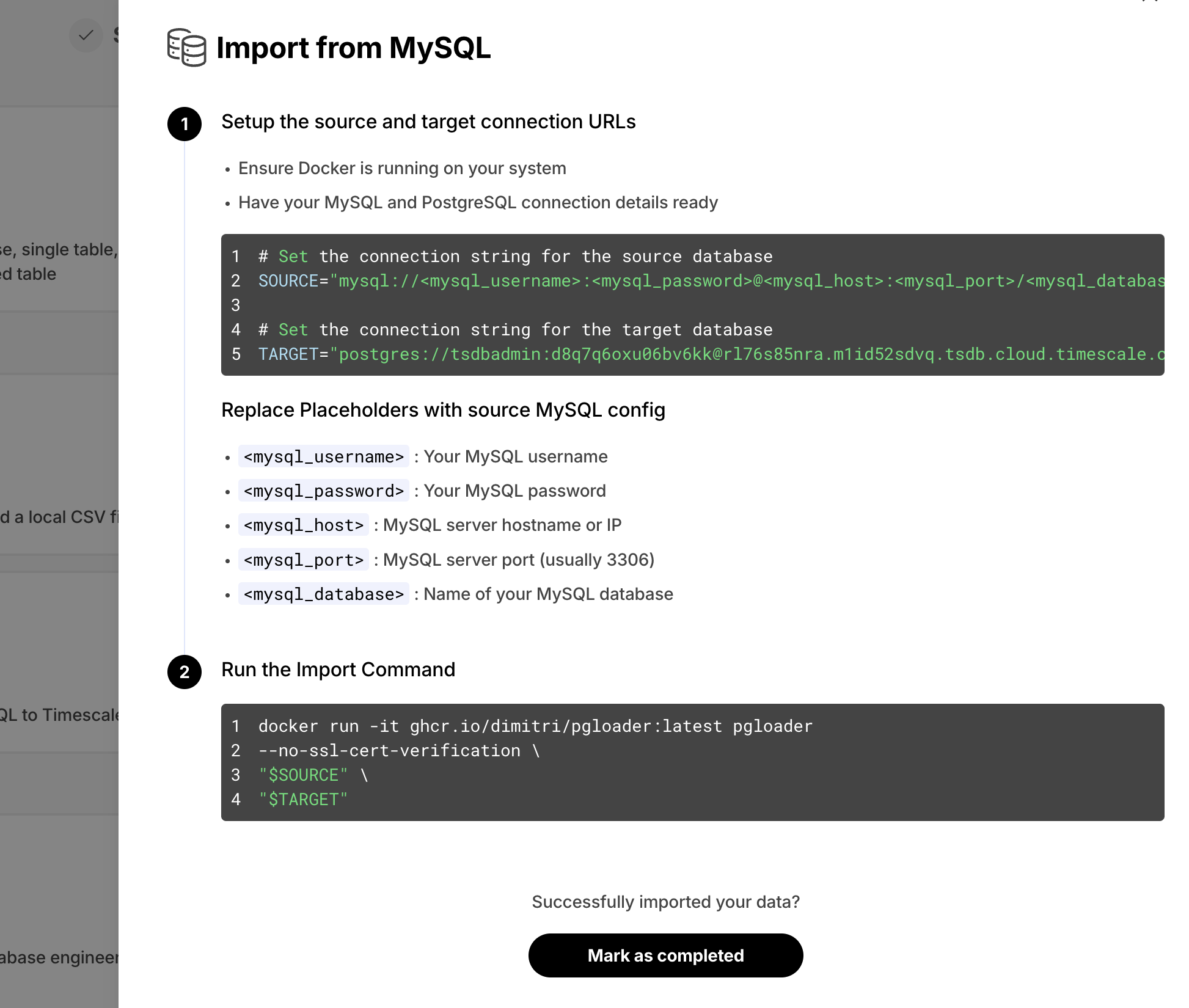
In Timescale Console, we offer the SQL editor so you can directly querying your service. As a new improvement, if a query is waiting on locks and can't complete execution, Timescale Console now displays the current lock contention in the results section .
Timescale now supports multiple CIDRs on the customer VPC. Customers who want to take advantage of multiple CIDRs will need to recreate their peering.
September 19, 2024We've been listening to your feedback and noticed that Timescale Console users have diverse needs. Some of you are focused on operational tasks like adding replicas or changing parameters, while others are diving deep into data analysis to gather insights.
To better serve you, we've introduced new modes to the Timescale Console UI—tailoring the experience based on what you're trying to accomplish.
Ops mode is where you can manage your services, add replicas, configure compression, change parameters, and so on.
Data mode is the full PopSQL experience: write queries with autocomplete, visualize data with charts and dashboards, schedule queries and dashboards to create alerts or recurring reports, share queries and dashboards, and more.
Try it today and let us know what you think!
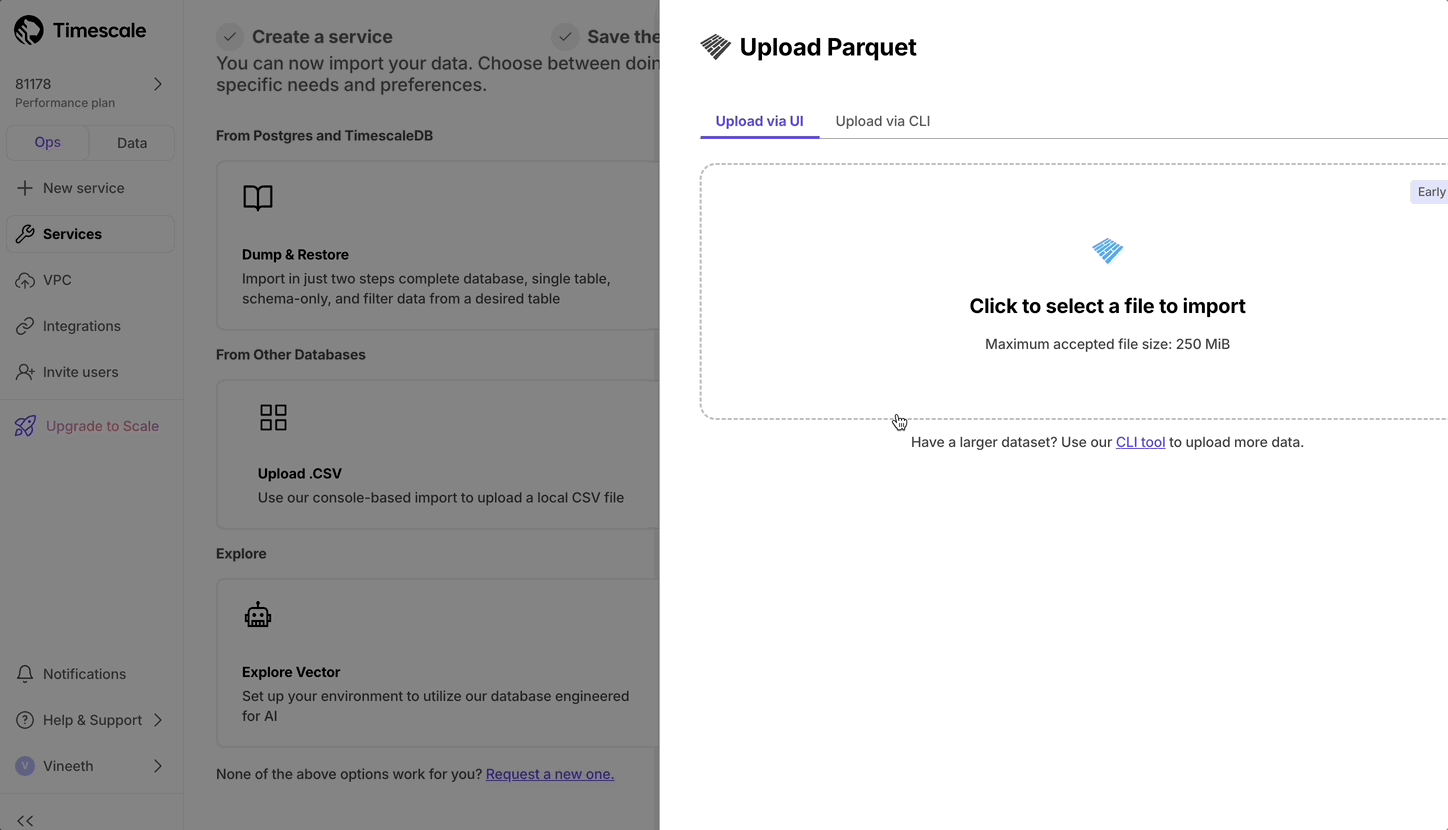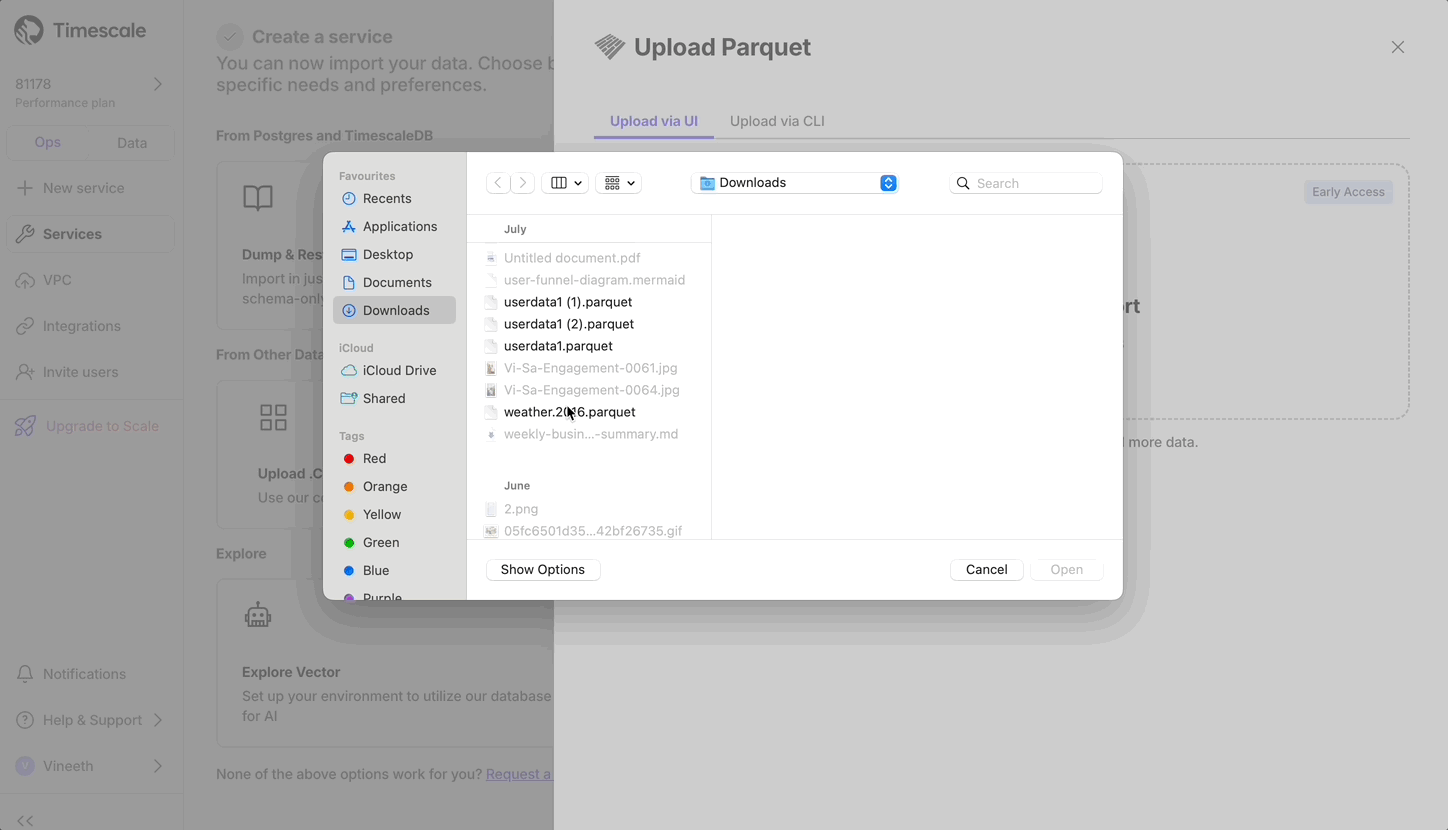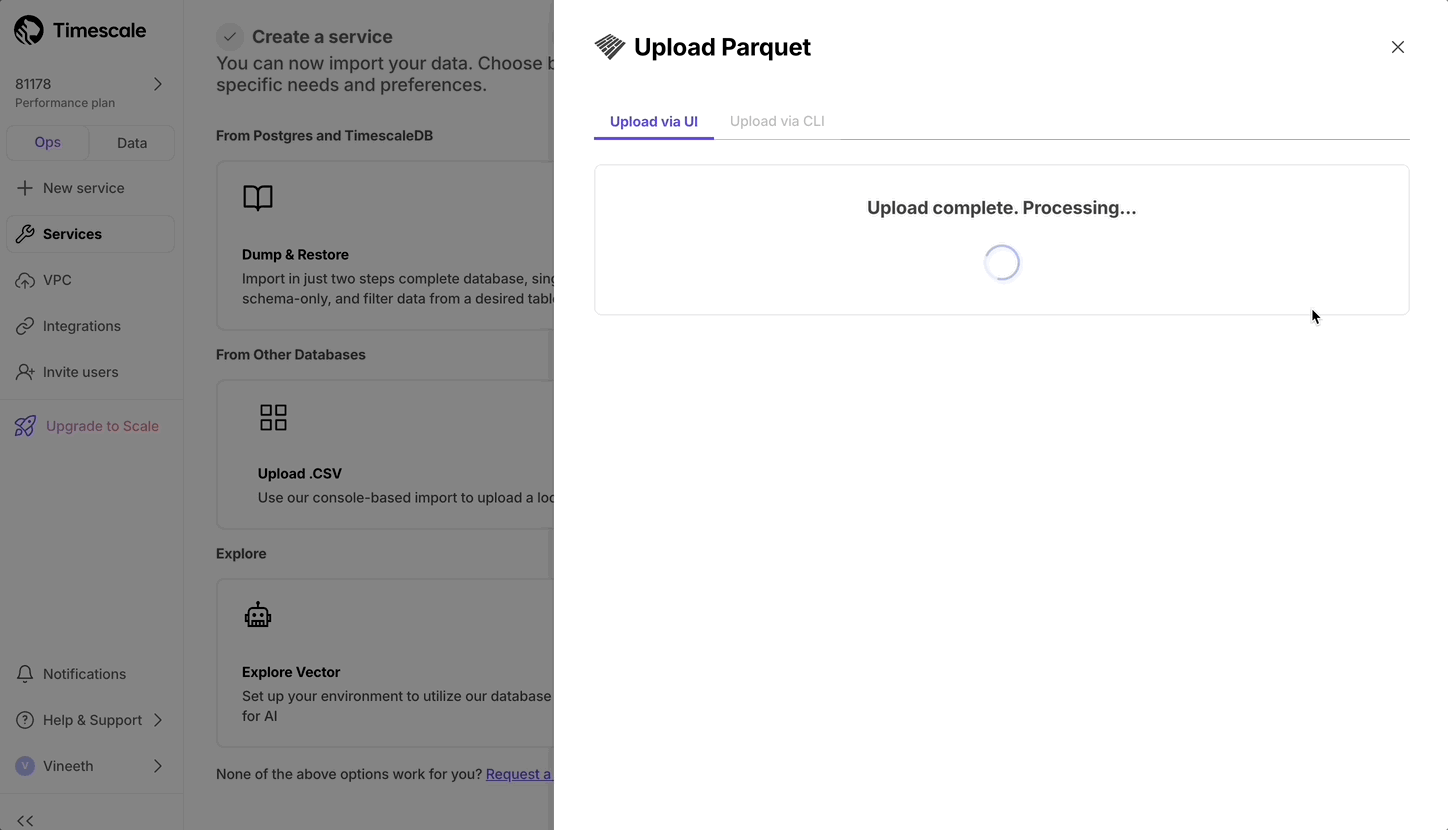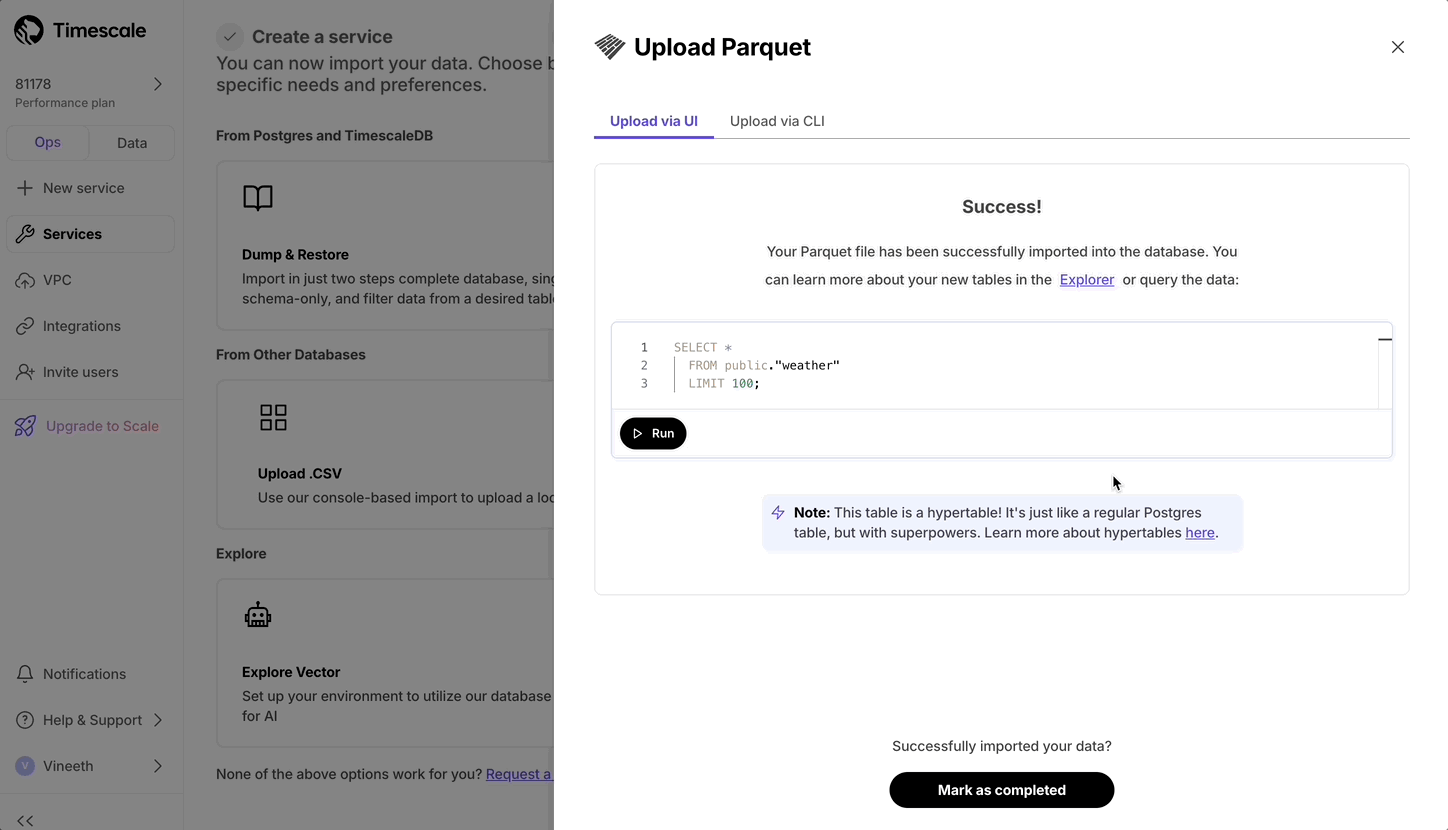
Now users can upload from Parquet to Timescale Cloud by uploading the file from their local file system. For files larger than 250 MB, or if you want to do it yourself, follow the three-step process to upload Parquet files to Timescale.
- In the Ops mode SQL editor, you can now highlight a statement to run a specific statement.
Scale and Enterprise customers can now configure two new multiple high availability (HA) replica options directly through Timescale Console:
- Two HA replicas (both asynchronous) - our highest availability configuration.
- Two HA replicas (one asynchronous, one synchronous) - our highest data integrity configuration.
Previously, Timescale offered only a single synchronous replica for customers seeking high availability. The single HA option is still available.


For more details on multiple HA replicas, see Manage high availability.
In the Console SQL editor, we now indicate if your database session is healthy or has been disconnected. If it's been disconnected, the session will reconnect on your next query execution.

Released live-migration v0.0.26 and then v0.0.27 which includes multiple performance improvements and bugfixes as well as better support for PostgreSQL 12.
Now you can simply click to run SQL statements in various places in the Console. This requires that the SQL Editor is enabled for the service.
Enable Continuous Aggregates from the CAGGs wizard by clicking Run below the SQL statement.

Enable database extensions by clicking Run below the SQL statement.

Query data instantly with a single click in the Console after successfully uploading a CSV file.

Last week we announced the new in-console SQL editor. However, there was a limitation where a new database session was created for each query execution.
Today we removed that limitation and added support for keeping one database session for each user logged in, which means you can do things like start transactions:
begin;insert into users (name, email) values ('john doe', 'john@example.com');abort; -- nothing inserted
Or work with temporary tables:
create temporary table temp_users (email text);insert into temp_sales (email) values ('john@example.com');-- table will automatically disappear after your session ends
Or use the set command:
set search_path to 'myschema', 'public';
We've added a new tab to the service screen that allows users to query their database directly, without having to leave the console interface.
- For existing services on Timescale, this is an opt-in feature. For all newly created services, the SQL Editor will be enabled by default.
- Users can disable the SQL Editor at any time by toggling the option under the Operations tab.
- The editor supports all DML and DDL operations (any single-statement SQL query), but doesn't support multiple SQL statements in a single query.

After service creation, we now offer a dedicated section for data import, including options to import from Postgres as a source or from CSV files.
The enhanced Postgres import instructions now offer several options: single table import, schema-only import, partial data import (allowing selection of a specific time range), and complete database import. Users can execute any of these data imports with just one or two simple commands provided in the data import section.

We've released v0.0.25 of Live migration that includes the following improvements:
- Support migrating tsdb on non public schema to public schema
- Pre-migration compatibility checks
- Docker compose build fixes
We have added a CSV import tool to the Timescale Console. For all TimescaleDB services, after service creation you can:
- Choose a local file
- Select the name of the data collection to be uploaded (default is file name)
- Choose data types for each column
- Upload the file as a new hypertable within your service
Look for the
Import data from .csvtile in theImport your datastep of service creation.

Customers now have more visibility into the state of replicas running on Timescale Cloud. We’ve released a new parameter called Replica Lag within the Service Overview for both Read and High Availability Replicas. Replica lag is measured in bytes against the current state of the primary database. For questions or concerns about the relative lag state of your replica, reach out to Customer Support.

Customers can now adjust their chunk interval for their hypertables and continuous aggregates through the Timescale UI. In the Explorer, select the corresponding hypertable you would like to adjust the chunk interval for. Under Chunk information, you can change the chunk interval. Note that this only changes the chunk interval going forward, and does not retroactively change existing chunks.

We've released permission granting via role assumption to CloudWatch. Role assumption is both more secure and more convenient for customers who no longer need to rotate credentials and update their exporter config.
For more details take a look at our documentation.

We’ve added a 2FA status column to the Members page, allowing customers to easily see whether each project member has 2FA enabled or disabled.

The pgai extension v0.3.0 now supports embedding creation and LLM reasoning using models from Anthropic and Cohere. For details and examples, see this post for pgai and Cohere, and this post for pgai and Anthropic.
pgvectorscale extension v0.3.0 adds support for ARM processors and improves recall when using StreamingDiskANN indexes with low dimensionality vectors. We recommend updating to this version if you are self-hosting.
August 15, 2024TimescaleDB v2.16.0 contains significant performance improvements when working with compressed data, extended join support in continuous aggregates, and the ability to define foreign keys from regular tables towards hypertables. We recommend upgrading at the next available opportunity.
Any new service created on Timescale Cloud starting today uses TimescaleDB v2.16.0.
In TimescaleDB v2.16.0 we:
Introduced multiple performance focused optimizations for data manipulation operations (DML) over compressed chunks.
Improved upsert performance by more than 100x in some cases and more than 500x in some update/delete scenarios.
Added the ability to define chunk skipping indexes on non-partitioning columns of compressed hypertables.
TimescaleDB v2.16.0 extends chunk exclusion to use these skipping (sparse) indexes when queries filter on the relevant columns, and prune chunks that do not include any relevant data for calculating the query response.
Offered new options for use cases that require foreign keys defined.
You can now add foreign keys from regular tables towards hypertables. We have also removed some really annoying locks in the reverse direction that blocked access to referenced tables while compression was running.
Extended Continuous Aggregates to support more types of analytical queries.
More types of joins are supported, additional equality operators on join clauses, and support for joins between multiple regular tables.
Highlighted features in this release
Improved query performance through chunk exclusion on compressed hypertables.
You can now define chunk skipping indexes on compressed chunks for any column with one of the following integer data types:
smallint,int,bigint,serial,bigserial,date,timestamp,timestamptz.After calling
enable_chunk_skippingon a column, TimescaleDB tracks the min and max values for that column, using this information to exclude chunks for queries filtering on that column, where no data would be found.Improved upsert performance on compressed hypertables.
By using index scans to verify constraints during inserts on compressed chunks, TimescaleDB speeds up some ON CONFLICT clauses by more than 100x.
Improved performance of updates, deletes, and inserts on compressed hypertables.
By filtering data while accessing the compressed data and before decompressing, TimescaleDB has improved performance for updates and deletes on all types of compressed chunks, as well as inserts into compressed chunks with unique constraints.
By signaling constraint violations without decompressing, or decompressing only when matching records are found in the case of updates, deletes and upserts, TimescaleDB v2.16.0 speeds up those operations more than 1000x in some update/delete scenarios, and 10x for upserts.
You can add foreign keys from regular tables to hypertables, with support for all types of cascading options. This is useful for hypertables that partition using sequential IDs, and need to reference these IDs from other tables.
Lower locking requirements during compression for hypertables with foreign keys
Advanced foreign key handling removes the need for locking referenced tables when new chunks are compressed. DML is no longer blocked on referenced tables while compression runs on a hypertable.
Improved support for queries on Continuous Aggregates
INNER/LEFTandLATERALjoins are now supported. Plus, you can now join with multiple regular tables, and have more than one equality operator on join clauses.
PostgreSQL 13 support removal announcement
Following the deprecation announcement for PostgreSQL 13 in TimescaleDB v2.13, PostgreSQL 13 is no longer supported in TimescaleDB v2.16.
The currently supported PostgreSQL major versions are 14, 15, and 16.
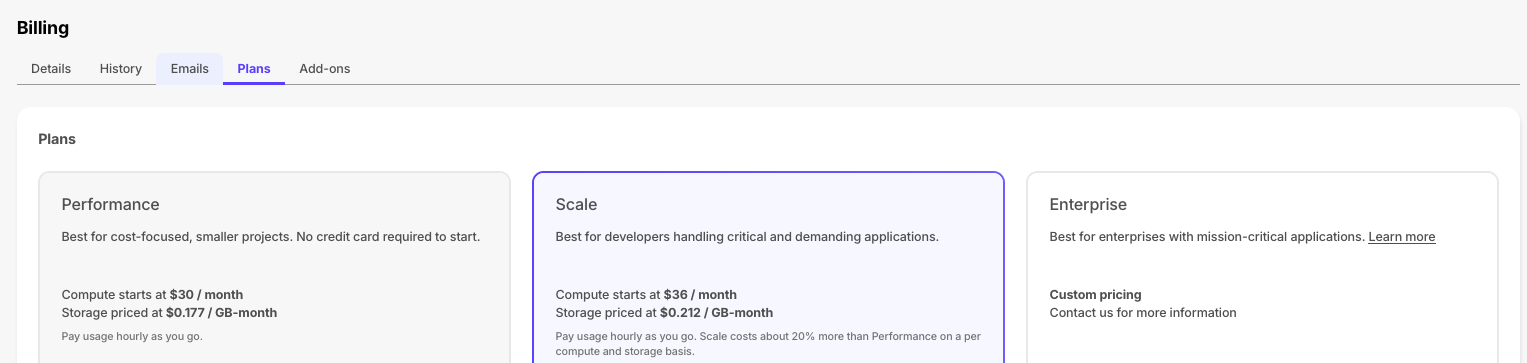
August 8, 2024To support evolving customer needs, Timescale Cloud now offers three plans to provide more value, flexibility, and efficiency.
- Performance: for cost-focused, smaller projects. No credit card required to start.
- Scale: for developers handling critical and demanding apps.
- Enterprise: for enterprises with mission-critical apps.
Each plan continues to bill based on hourly usage, primarily for compute you run and storage you consume. You can upgrade or downgrade between Performance and Scale plans via the Console UI at any time. More information about the specifics and differences between these pricing plans can be found here in the docs.
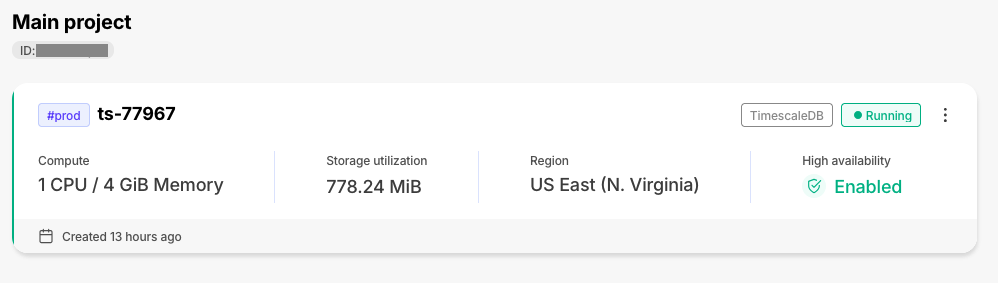
The individual tiles on the services page have been enhanced with new information, including high-availability status. This will let you better assess the state of your services at a glance.
Improvements:
- Automatic retries are now available for the initial data copy of the migration
- Now uses pgcopydb for initial data copy for PG to TSDB migrations also (already did for TS to TS) which has a significant performance boost.
- Fixes issues with TimescaleDB v2.13.x migrations
- Support for chunk mapping for hypertables with custom schema and table prefixes
The following improvements have been made to Timescale products:
Timescale Cloud:
- The connection pooler has been updated and now avoids multiple reloads
- The tsdbadmin user can now grant the following roles to other users:
pg_checkpoint,pg_monitor,pg_signal_backend,pg_read_all_stats,pg_stat_scan_tables - Timescale Console is far more reliable.
TimescaleDB
- The TimescaleDB v2.15.3 patch release improves handling of multiple unique indexes in a compressed INSERT, removes the recheck of ORDER when querying compressed data, improves memory management in DML functions, improves the tuple lock acquisition for tiered chunks on replicas, and fixes an issue with ORDER BY/GROUP BY in our HashAggregate optimization on PG16. For more information, see the release note.
- The TimescaleDB v2.15.2 patch release improves sort pushdown for partially compressed chunks, and compress_chunk with a primary space partition. The metadata function is removed from the update script, and hash partitioning on a primary column is disallowed. For more information, see the release note.
The following improvements have been made to the Timescale live-migration docker image:
- Table-based filtering is now available during live migration.
- Improvements to pbcopydb increase performance and remove unhelpful warning messages.
- The user notification log enables you to always select the most recent release for a migration run.
For improved stability and new features, update to the latest timescale/live-migration docker image. To learn more, see the live migration docs.
June 21, 2024Ollama is now integrated with pgai.
Ollama is the easiest and most popular way to get up and running with open-source language models. Think of Ollama as Docker for LLMs, enabling easy access and usage of a variety of open-source models like Llama 3, Mistral, Phi 3, Gemma, and more.
With the pgai extension integrated in your database, embed Ollama AI into your app using SQL. For example:
select ollama_generate( 'llava:7b', 'Please describe this image.', _images=> array[pg_read_binary_file('/pgai/tests/postgresql-vs-pinecone.jpg')], _system=>'you are a helpful assistant', _options=> jsonb_build_object( 'seed', 42, 'temperature', 0.9))->>'response';
To learn more, see the pgai Ollama documentation.
June 13, 2024The compression wizard is now available on Timescale Cloud. Select a hypertable and be guided through enabling compression through the UI!
To access the compression wizard, navigate to Explorer, and select the hypertable you would like to compress. In the top right corner, hover where it says Compression off, and open the wizard. You will then be guided through the process of configuring compression for your hypertable, and can compress it directly through the UI.

The vectorscale extension is now available on Timescale Cloud.
pgvectorscale complements pgvector, the open-source vector data extension for PostgreSQL, and introduces the following key innovations for pgvector data:
- A new index type called StreamingDiskANN, inspired by the DiskANN algorithm, based on research from Microsoft.
- Statistical Binary Quantization: developed by Timescale researchers, This compression method improves on standard Binary Quantization.
On benchmark dataset of 50 million Cohere embeddings (768 dimensions each), PostgreSQL with pgvector and pgvectorscale achieves 28x lower p95 latency and 16x higher query throughput compared to Pinecone's storage optimized (s1) index for approximate nearest neighbor queries at 99% recall, all at 75% less cost when self-hosted on AWS EC2.
To learn more, see the pgvectorscale documentation.
June 11, 2024The pgai extension is now available on Timescale Cloud.
pgai brings embedding and generation AI models closer to the database. With pgai, you can now do the following directly from within PostgreSQL in a SQL query:
- Create embeddings for your data.
- Retrieve LLM chat completions from models like OpenAI GPT4o.
- Reason over your data and facilitate use cases like classification, summarization, and data enrichment on your existing relational data in PostgreSQL.
To learn more, see the pgai documentation.
June 7, 2024The 2.15.x releases contains performance improvements and bug fixes. Highlights in these releases are:
- Continuous Aggregate now supports
time_bucketwith origin and/or offset. - Hypertable compression has the following improvements:
- Recommend optimized defaults for segment by and order by when configuring compression through analysis of table configuration and statistics.
- Added planner support to check more kinds of WHERE conditions before decompression. This reduces the number of rows that have to be decompressed.
- You can now use minmax sparse indexes when you compress columns with btree indexes.
- Vectorize filters in the WHERE clause that contain text equality operators and LIKE expressions.
To learn more, see the TimescaleDB release notes.
May 31, 2024The PostgreSQL Audit extension(pgaudit) is now available on Timescale Cloud. pgaudit provides detailed database session and object audit logging in the Timescale Cloud logs.
If you have strict security and compliance requirements and need to log all operations on the database level, pgaudit can help. You can also export these audit logs to Amazon CloudWatch.
To learn more, see the pgaudit documentation.
May 31, 2024The SI Units for PostgreSQL extension(unit) provides support for the ISU in Timescale Cloud.
You can use Timescale Cloud to solve day-to-day questions. For example, to see what 50°C is in °F, run the following query in your Timescale Cloud service:
SELECT '50°C'::unit @ '°F' as temp;temp--------122 °F(1 row)
To learn more, see the postgresql-unit documentation.
Keywords
Found an issue on this page?Report an issue or Edit this page in GitHub.