Managed Service for TimescaleDB (MST) is TimescaleDB hosted on Azure and GCP. MST is offered in partnership with Aiven.
Timescale Cloud or MST?
Timescale Cloud is a high-performance developer focused cloud that provides PostgreSQL services enhanced with our blazing fast vector search. You can securely integrate Timescale Cloud with your AWS, GCS or Azure infrastructure. Create a Timescale Cloud service and try for free.
If you need to run TimescaleDB on GCP or Azure, you're in the right place — keep reading.
Your Managed Service for TimescaleDB account has three main components: projects, services, and databases.
When you sign up for Managed Service for TimescaleDB, an empty project is created for you automatically. Projects are the highest organization level, and they contain all your services and databases. You can use projects to organize groups of services. Each project can also have its own billing settings.
To create a new project: In MST Console, click Projects > Create project.
Each project contains one or more services. You can have multiple services under
each project, and each service corresponds to a cloud service provider tier. You
can access all your services from the Services tab within your projects.
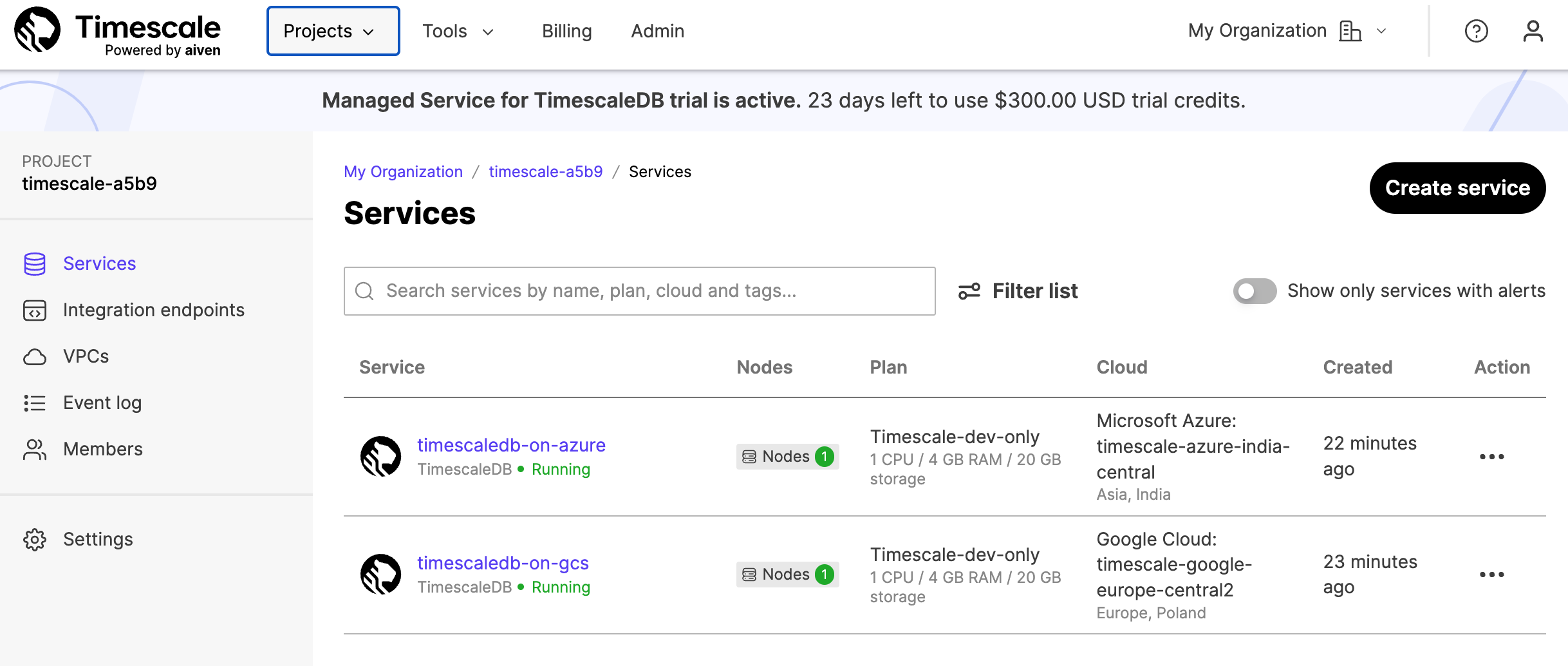
For more information about getting your first service up and running, see the Managed Service for Timescale installation section.

Important
When you have created, and named, a new Managed Service for TimescaleDB service, you cannot rename it. If you need to have your service running under a different name, you need to create a new service, and manually migrate the data. For more information about migrating data, see migrating your data.
For information about billing on Managed Service for TimescaleDB, see the billing section.
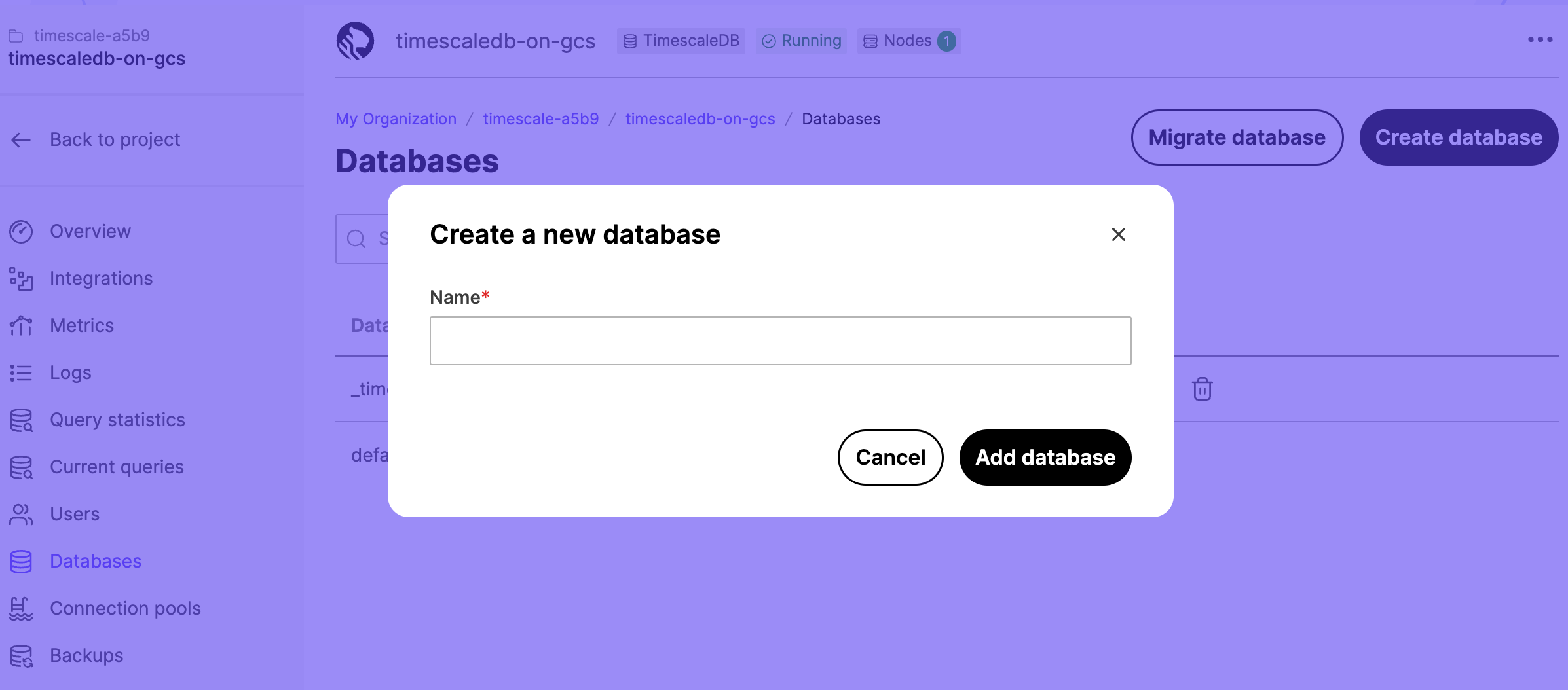
Each service can contain one or more databases. To view existing databases, or
to create a new database, select a service in the services list,
click Databases, then click Create database.
Managed Service for TimescaleDB is provided through a partnership with Aiven. This provides you with a service commitment to deliver 99.99% availability. For more information, see the Aiven Service Level Agreement policy.
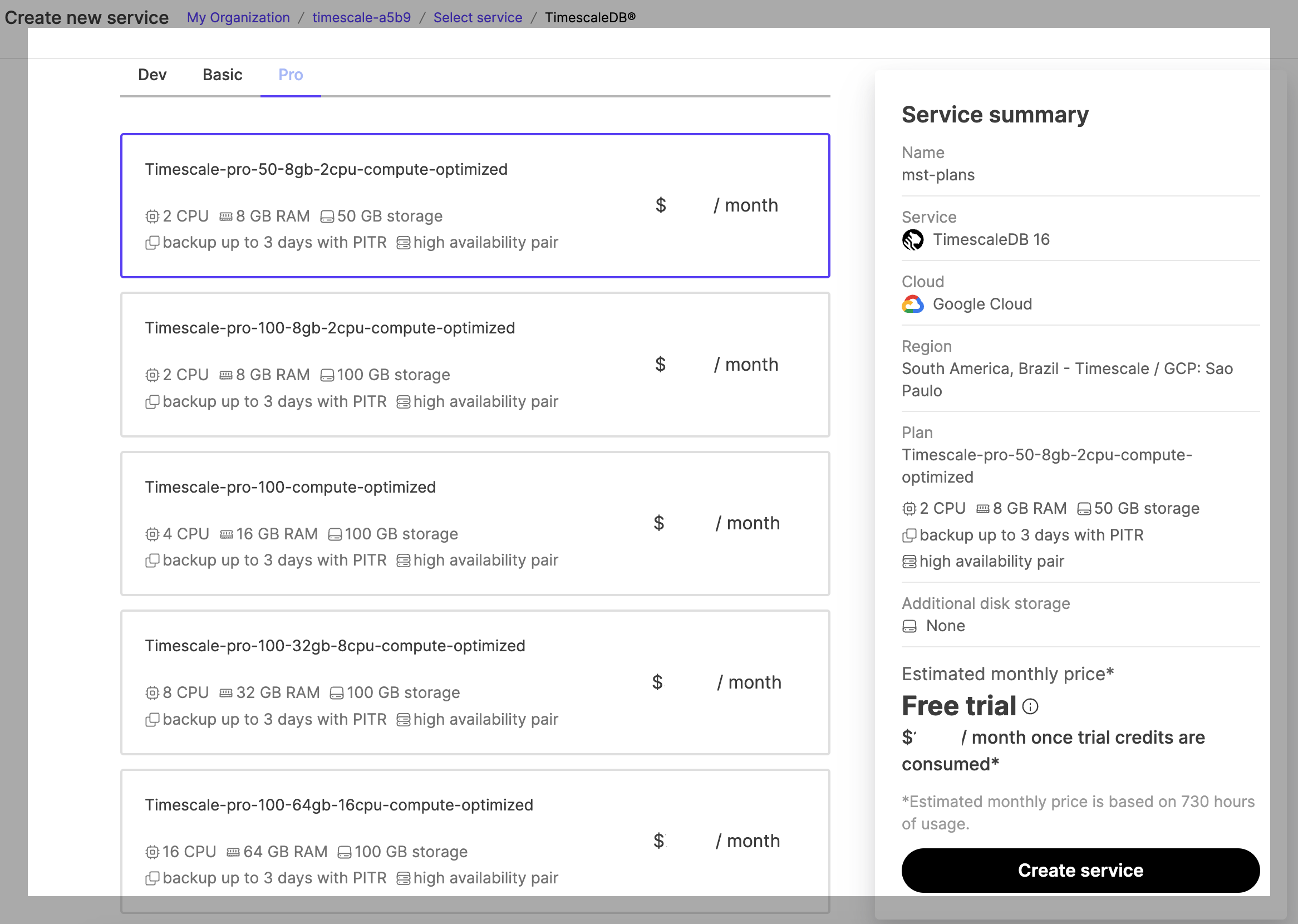
When you create a new service, you need to select a configuration plan. The plan determines the number of VMs the service runs in, the high availability configuration, the number of CPU cores, and size of RAM and storage volumes.
The plans are:
- Basic Plans: include 2 days of backups and automatic backup and restore if your instance fails.
- Dev Plans: include 1 day of backups and automatic backup and restore if your instance fails.
- Pro Plans: include 3 days of backups and automatic failover to a hot standby if your instance fails.
The Basic and Dev plans are serviced by a single virtual machine (VM) node. This means that if the node fails, the service is unavailable until a new VM is built. This can result in data loss, if some of the latest changes to the data weren't backed up before the failure. Sometimes, it can also take a long time to return the service back to normal operation, because a new VM needs to be created and restored from backups before the service can resume. The time to recover depends on the amount of data you have to restore.
The Pro plans are much more resilient to failures. A single node failure causes no data loss, and the possible downtime is minimal. If an acting TimescaleDB master node fails, an up-to-date replica node is automatically promoted to become the new master. This means there is only a small outage while applications reconnect to the database and access the new master.
You can upgrade your plan while the service is running. The service is reconfigured to run on larger VMs in the background and when the reconfiguration is complete, the DNS names are pointed to the new hosts. This can cause a short disruption to your service while DNS changes are propagated.
Within each configuration plan option, there are several plan types available:
IO-OptimizedandCompute-OptimizedThese configurations are optimized for input/output (I/O) performance, using SSD storage media.Storage-Optimized: These configurations usually have larger amounts of overall storage, using HDD storage media.Dev-Only: These configurations are typically smaller footprints, and lower cost, designed for development and testing scenarios.
Most minor failures are handled automatically without making any changes to your service deployment. This includes failures such as service process crashes, or a temporary loss of network access. The service automatically restores normal operation when the crashed process restarts automatically or when the network access is restored.
However, more severe failure modes, such as losing a single node entirely, require more drastic recovery measures. Losing an entire node or a virtual machine could happen for example due to hardware failure or a severe software failure.
A failing node is automatically detected by the MST monitoring infrastructure. Either the node starts reporting that its own self-diagnostics is reporting problems or the node stops communicating entirely. The monitoring infrastructure automatically schedules a new replacement node to be created when this happens.

Note
In case of database failover, the service URL of your service remains the same. Only the IP address changes to point at the new master node.
Managed Service for TimescaleDB availability features differ based on the service plan:
- Basic and Dev plans: These are single-node plans. Basic plans include a two-day backup history, and Dev plans include a one-day backup history.
- Pro plans: These are two-node plans with a master and a standby for higher availability, and three-day backup histories.
In the Basic and Dev plans, if you lose the only node from the service, it immediately starts the automatic process of creating a new replacement node. The new node starts up, restores its state from the latest available backup, and resumes the service. Because there was just a single node providing the service, the service is unavailable for the duration of the restore operation. Also, any writes made since the backup of the latest write-ahead log (WAL) file is lost. Typically this time window is limited to either five minutes, or one WAL file.
In Pro plans, if a PostgreSQL standby fails, the master node keeps running normally and provides normal service level to the client applications. When the new replacement standby node is ready and synchronized with the master, it starts replicating the master in real time and normal operation resumes.
If the PostgreSQL master fails, the combined information from the MST monitoring
infrastructure and the standby node is used to make a failover decision. On the
nodes, the open source monitoring daemon PGLookout, in combination with the
information from the MST system infrastructure, reports the failover. If the
master node is down completely, the standby node promotes itself as the new
master node and immediately starts serving clients. A new replacement node is
automatically scheduled and becomes the new standby node.
If both master and standby nodes fail at the same time, two new nodes are automatically scheduled for creation and become the new master and standby nodes respectively. The master node restores itself from the latest available backup, which means that there can be some degree of data loss involved. For example, any writes made since the backup of the latest write-ahead log (WAL) file can be lost.
The amount of time it takes to replace a failed node depends mainly on the cloud region and the amount of data that needs to be restored. However, in the case of services with two-node Pro plans, the surviving node keeps serving clients even during the recreation of the other node. This process is entirely automatic and requires no manual intervention.
For backups and restoration, Managed Service for TimescaleDB uses the
open source backup daemon PGHoard that MST maintains. It makes real-time
copies of write-ahead log (WAL) files to an object store in a compressed and
encrypted format.
Managed Service for TimescaleDB limits the maximum number of connections to each
service. The maximum number of allowed connections depends on your service plan.
To see the current connection limit for your service, navigate to the service
Overview tab and locate the Connection Limit section.
If you have a lot of clients or client threads connecting to your database, use connection pooling to limit the number of connections. For more information about connection pooling, see the connection pooling section.
Note
If you have a high number of connections to your database, your service might run more slowly, and could run out of memory. Remain aware of how many open connections your have to your database at any given time.
You can protect your services from accidentally being terminated, by enabling service termination protection. When termination protection is enabled, you cannot power down the service from the web console, the REST API, or with a command-line client. To power down a protected service, you need to turn off termination protection first. Termination protection does not interrupt service migrations or upgrades.
To enable service termination protection, navigate to the service Overview
tab. Locate the Termination protection section, and toggle to enable
protection.
Important
If you run out of free sign-up credit, and have not entered a valid credit card for payment, your service is powered down, even if you have enabled termination protection.
Managed Service for TimescaleDB uses the default keep alive settings for TCP connections. The default settings are:
tcp_keepalives_idle: 7200tcp_keepalive_count: 9tcp_keepalives_interval: 75
If you have long idle database connection sessions, you might need to adjust these settings to ensure that your TCP connection remains stable. If you experience a broken TCP connection, when you reconnect make sure that your client resolves the DNS address correctly, as the underlying address changes during automatic failover.
For more information about adjusting keep alive settings, see the PostgreSQL documentation.
Managed Service for TimescaleDB does not cancel database queries. If you have created a query that is taking a very long time, or that has hung, it could lock resources on your service, and could prevent database administration tasks from being performed.
You can find out if you have any long-running queries by navigating to the
service Current Queries tab. You can also cancel long running queries from
this tab.
Alternatively, you can use your connection client to view running queries with this command:
SELECT * FROM pg_stat_activityWHERE state <> 'idle';
Cancel long-running queries using this command, with the PID of the query you want to cancel:
SELECT pg_terminate_backend(<PID>);
If you want to automatically cancel any query that runs over a specified length of time, you can use this command:
SET statement_timeout = <milliseconds>
Keywords
Found an issue on this page?Report an issue or Edit this page in GitHub.