All Timescale services come with a rapid recovery feature enabled by default. Rapid recovery ensures that all services experience minimal downtime and data loss in the most common failure scenarios and during maintenance. For services with very low tolerance for downtime, Timescale offers high availability (HA) replicas. HA replicas significantly reduce the risk of downtime and data loss due to failures, and allow a service to avoid downtime for routine maintenance. This section covers how each of these work to help you make an informed decision about which is right for your service.
HA replicas are exact, up-to-date copies of your database that automatically take over operations if your primary becomes unavailable, including during maintenance. In technical terms, HA replicas are multi-AZ, asynchronous hot standbys. They use streaming replication to minimize the chance of data loss during failover. There is more information on these terms later in this section.
HA replicas also have a separate unique address that you can use to serve read requests, but this read-only unique address is not highly available during failures. That is, when an HA-replicated primary fails and your connection automatically "fails over" to the former HA replica, the read-only unique address is no longer accessible until a new HA replica is fully recovered. This recovery happens automatically but its recovery period is dependent on several factors, including database size.
Some operations on your database cannot avoid downtime, such as upgrading to a new major version of PostgreSQL. For routine maintenance, like upgrading to a new minor version of PostgreSQL, a service restart may be required, but this only happens during the maintenance window you set.
Adding an HA replica to your service prevents downtime during maintenance events, as maintenance is applied to each node individually. For example, your replica can have maintenance performed on it while the primary remains operational. When the maintenance is completed, the replica is promoted to the primary and the other node undergoes maintenance.
- Log in to your Timescale account and click the service you want to replicate.
- Navigate to the
Operationstab, and selectHigh availability. - Check the pricing of the replica, and click
Add a replica. Confirm the action by clickingAdd replica. - You can see the replicas for each service by clicking on the service name,
navigating to the
Operationstab, and selectingHigh availability. Replicas are not shown in the mainServicessection, as they are not independent. - You can see connection information for the replica by navigating to the
Overviewtab. In theConnection infosection, select the replica from theRoledrop-down menu to populate the section with the replica's connection details.
Failover is the process of redirecting traffic from your primary to the HA replica within 15 seconds of the primary becoming unresponsive. As part of failover, the HA replica is promoted to become the new primary and the connection is reset. In the background, a new replica is immediately provisioned for the new primary.
Failover also helps remove downtime for common operations which would normally cause a service to reset, like maintenance events and service resizes. In these cases, changes are made to each node sequentially so that there is always a node available.
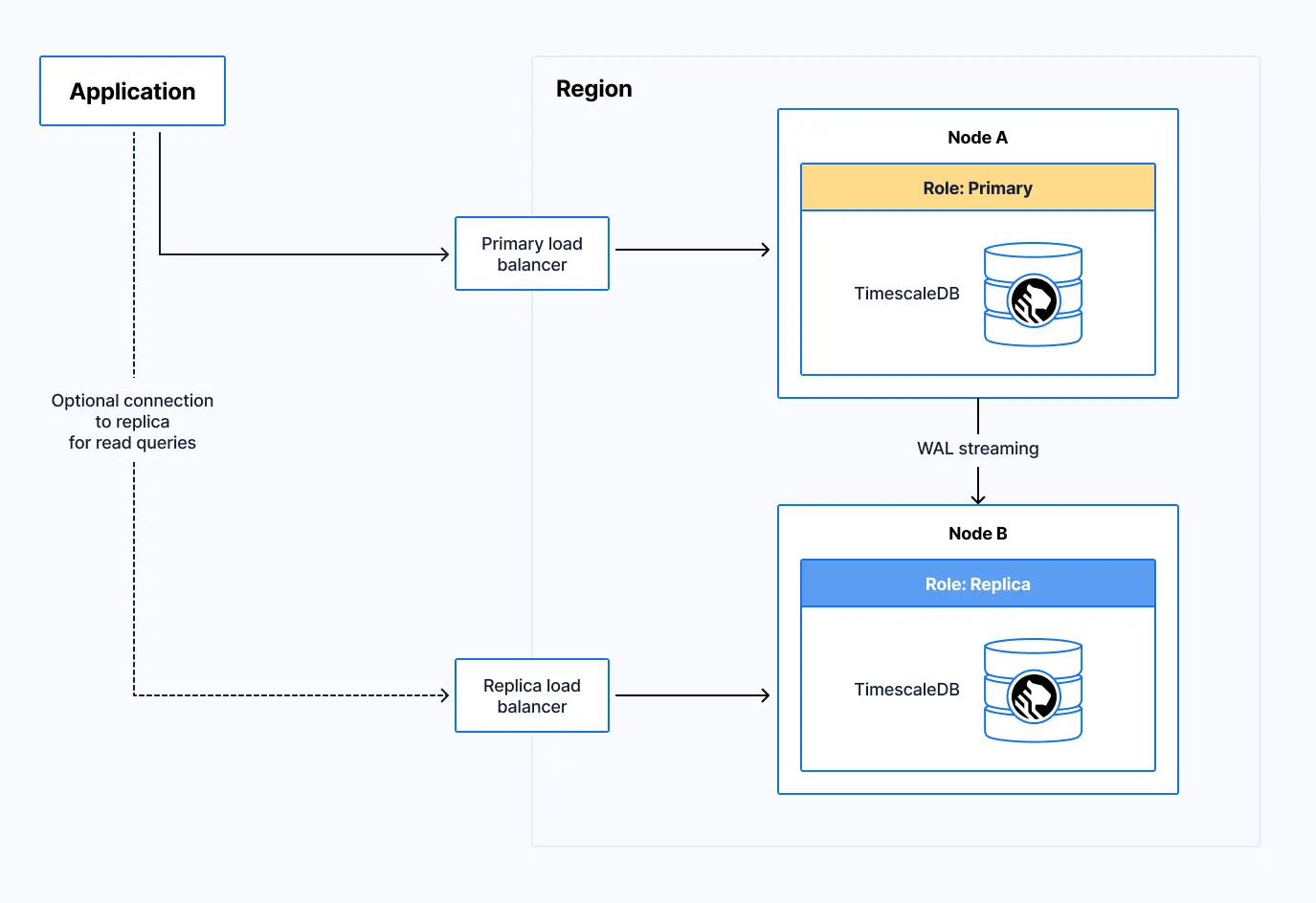
In a normal operating state, the application is connected to the primary and optionally to its replica. The load balancer handles the connection and defines the role for each node.
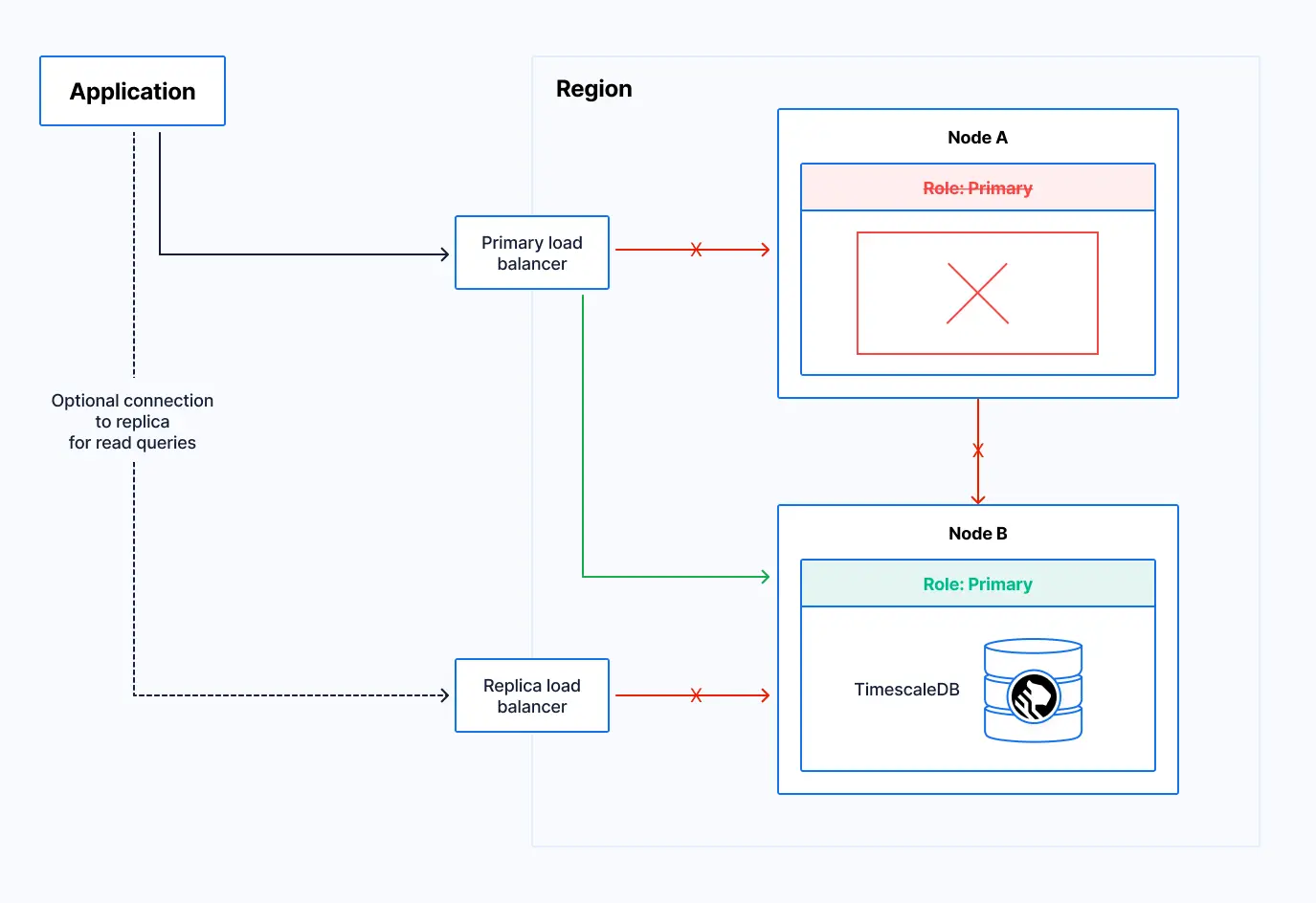
When the primary database fails, the platform updates the roles. The replica is promoted to the primary role, and the primary load balancer redirects traffic to the new primary. In the meantime, the system begins recovery of the failed node. The former read-replica connection remains unavailable until replica recovery completes.
When the failed node recovers or a new node is created, it assumes the replica role. The previously promoted node remains the primary, streaming the WAL (write-ahead log) to its replica. The read-replica connection becomes available again.
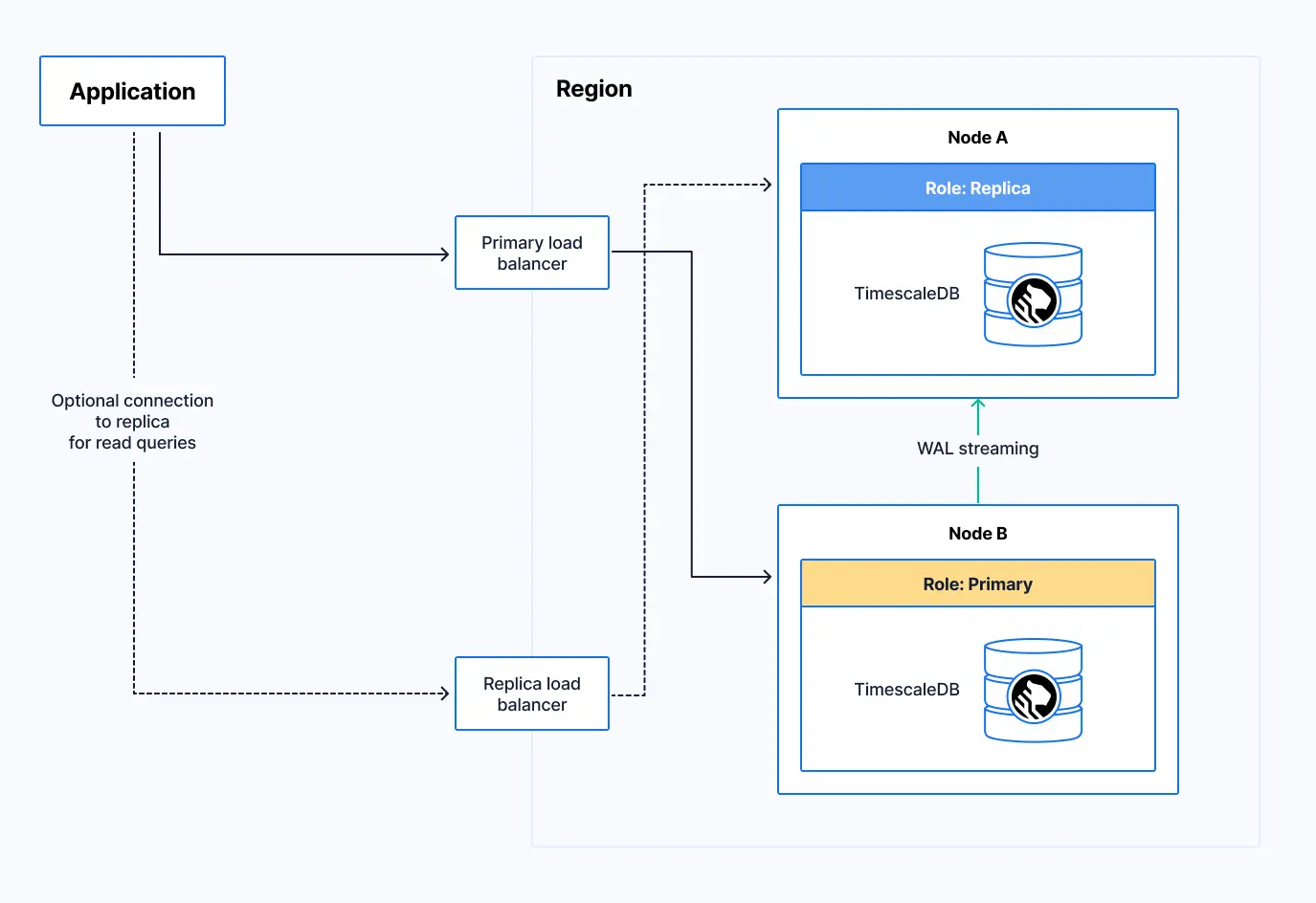
The new replica is created in a new availability zone to help protect against an availability zone outage.
To test the failover mechanism, you can trigger a switchover. A switchover is a safe operation that attempts a failover, and throws an error if the replica or primary is not in a state to safely switch.
Connect to your primary node as
tsdbadminor another user that is part of thetsdbownergroup.
Note
You can also connect to the HA replica and check its node using this procedure.
At the
psqlprompt, connect to thepostgresdatabase:\c postgresYou should see
postgres=>prompt.Check if your instance is currently in recovery:
select pg_is_in_recovery();Check which node is currently your primary:
select * from pg_stat_replication;Note the
application_name. This is your service ID followed by the node. The important part is the-an-0or-an-1.Schedule a switchover:
CALL tscloud.cluster_switchover();By default, the switchover occurs in 30 secs. You can change the time by passing an interval, like this:
CALL tscloud.cluster_switchover('15 seconds'::INTERVAL);Wait for the switchover to occur, then check which node is your primary:
SELECT * FROM pg_stat_replication;You should see a notice that your connection has been reset, like this:
FATAL: terminating connection due to administrator commandSSL connection has been closed unexpectedlyThe connection to the server was lost. Attempting reset: Succeeded.Check the
application_name. If your primary was-an-1before, it should now be-an-0. If it was-an-0, it should now be-an-1.
By default, all Timescale services have rapid recovery enabled. Because compute and storage are handled separately, there are different approaches available for different types of failures, and you don't always have to recover from backup. In particular, Timescale services recover quickly from compute failures, but usually need a full recovery from backup for storage failures.
Compute failures are the most common cause of database failure. Compute failures can be caused by hardware failing, or through things like unoptimized queries, causing increased load that maxes out the CPU usage. In these cases, only the compute and memory needs replacing since the data on disk is unaffected. If this kind of failure occurs, your Timescale service immediately provisions a new database instance and mounts the database's existing storage to the new instance. Any WAL that was in memory then replays. This process typically only takes thirty seconds, though it may take up to twenty minutes in some circumstances, depending on the amount of WAL that needs replaying. Even in the worst-case scenario, this recovery is an order of magnitude faster than a standard recovery from backup procedure. The entire process for detecting and recovering from a compute failure like this is fully automated, and you don't need to take any action.
While compute failures are more common, it is also possible for disk hardware to fail. This is rare, but if it happens, your Timescale service automatically performs a full recovery from backup. For more information about backup and recovery, see the backup section.

Important
Always try to avoid situations that could max out your CPU usage. If your CPU usage runs high for long periods of time, it can result in some issues, such as WAL archiving getting queued behind other processes, which can cause a failure and could result in a larger data loss. Timescale services are monitored for these kinds of scenarios, to try and prevent data loss events before a failure occurs.
HA replicas are multi-AZ, asynchronous hot standbys. They use streaming replication to minimize the chance of data loss during failover. This section defines those terms in a little more detail.
Timescale HA replicas are asynchronous. That means the primary database reports success once a transaction is completed locally. It doesn't wait to see if the replica successfully commits the transaction as well. This improves ingest rates and allows you to keep writing to your database even if a node fails.
Timescale doesn't currently offer synchronous replicas.
Timescale replicas are hot standbys. That means they are ready to take over when the primary fails. It also means you can read from your replica, even when the primary is running. You can reduce the load on your primary by distributing your read queries.
To keep data in sync between the primary and the replicas, the primary streams its write-ahead log (WAL). WAL records are streamed as soon as they're written rather than waiting to be batched and shipped. This reduces the chance of data loss.
By default, Timescale replicas are created in a different availability zone (AZ) than the primary. This provides additional availability for Timescale Cloud services with replicas, as it protects against entire AZ outages. If a primary is in an AZ that experiences an outage, the service can easily fail over to the replica.
Keywords
Found an issue on this page?Report an issue or Edit this page in GitHub.