Timescale Cloud: Performance, Scale, Enterprise
Self-hosted products
MST
Real-time analytics applications require more than fast inserts and analytical queries. They also need high performance when retrieving individual records, enforcing constraints, or performing upserts, something that OLAP/columnar databases lack.
- Segmenting and ordering data - improve performance by controlling the way data is physically stored.
To improve query performance using indexes for a production environment, see About indexes and Indexing data.
To optimize query performance, TimescaleDB enables you to explicitly control the way your data is physically organized in the columnstore. By structuring data effectively, queries can minimize disk reads and execute more efficiently, using vectorized execution for parallel batch processing where possible.
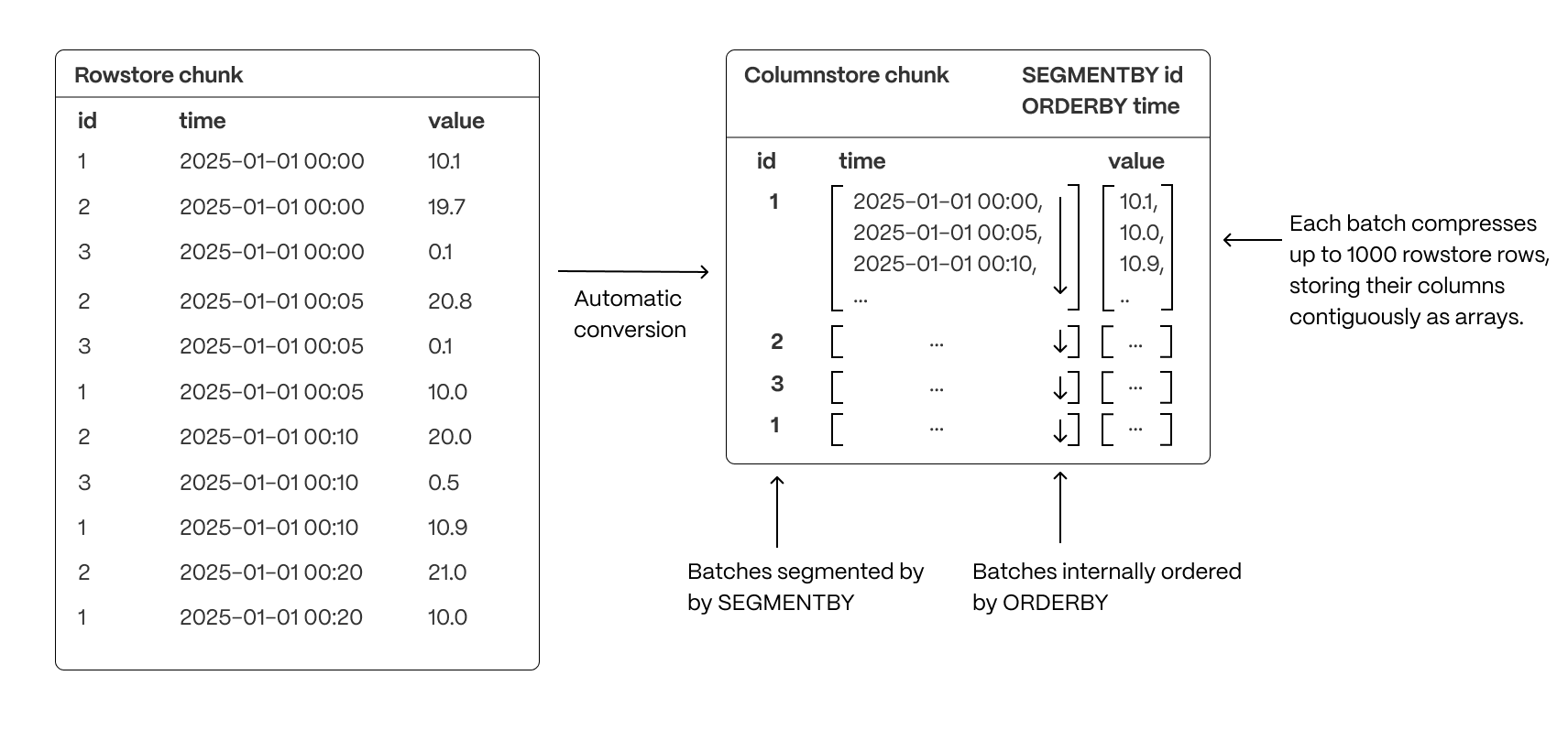
- Group related data together to improve scan efficiency: organizing rows into logical segments ensures that queries filtering by a specific value only scan relevant data sections. For example, in the above, querying for a specific ID is particularly fast.
- Sort data within segments to accelerate range queries: defining a consistent order reduces the need for post-query sorting, making time-based queries and range scans more efficient.
- Reduce disk reads and maximize vectorized execution: a well-structured storage layout enables efficient batch processing (Single Instruction, Multiple Data, or SIMD vectorization) and parallel execution, optimizing query performance.
By combining segmentation and ordering, TimescaleDB ensures that columnar queries are not only fast but also resource-efficient, enabling high-performance real-time analytics.
Ordering data in the columnstore has a large impact on the compression ratio and performance of your queries. Rows that change over a dimension should be close to each other. As hypertables contain time-series data, they are partitioned by time. This makes the time column a perfect candidate for ordering your data since the measurements evolve as time goes on.
If you use orderby as your only columnstore setting, you get a good enough compression ratio to save a lot of
storage and your queries are faster. However, if you only use orderby, you always have to access your data using the
time dimension, then filter the rows returned on other criteria.
Accessing the data effectively depends on your use case and your queries. You segment data in the columnstore to match the way you want to access it. That is, in a way that makes it easier for your queries to fetch the right data at the right time. When you segment your data to access specific columns, your queries are optimized and yield even better performance.
For example, to access information about a single device with a specific device_id, you segment on the device_id column.
This enables you to run analytical queries on compressed data in the columnstore much faster.
For example for the following hypertable:
CREATE TABLE metrics (time TIMESTAMPTZ,user_id INT,device_id INT,data JSONB) WITH (tsdb.hypertable,tsdb.partition_column='time');
Execute a query on a regular hypertable
- Query your dataGives the following result:SELECT device_id, AVG(cpu) AS avg_cpu, AVG(disk_io) AS avg_disk_ioFROM metricsWHERE device_id = 5GROUP BY device_id;device_id | avg_cpu | avg_disk_io-----------+--------------------+---------------------5 | 0.4972598866221261 | 0.49820356730280524(1 row)Time: 177,399 ms
- Query your data
Execute a query on the same data segmented and ordered in the columnstore
Control the way your data is ordered in the columnstore:
ALTER TABLE metrics SET (timescaledb.enable_columnstore = true,timescaledb.orderby = 'time',timescaledb.segmentby = 'device_id');Query your data
select avg(cpu) from metrics where time >= '2024-03-01 00:00:00+01' and time < '2024-03-02 00:00:00+01';Gives the following result:
device_id | avg_cpu | avg_disk_io-----------+-------------------+---------------------5 | 0.497259886622126 | 0.49820356730280535(1 row)Time: 42,139 ms
As you see, using
orderbyandsegmentbynot only reduces the amount of space taken by your data, but also vastly improves query speed.
The number of rows that are compressed together in a single batch (like the ones we see above) is 1000. If your chunk does not contain enough data to create big enough batches, your compression ratio will be reduced. This needs to be taken into account when you define your columnstore settings.
Deprecated since TimescaleDB v2.21.0 This feature is sunsetted in TimescaleDB v2.22.0.TimescaleDB supports and accelerates real-time analytics using hypercore without missing out on important
PostgreSQL features, including support for standard PostgreSQL indexes. Hypercore is a hybrid storage engine
because it supports deep analytics while staying true to PostgreSQL. Full support for B-tree and hash indexes
on columnstore data enables you to perform point lookups 1,185x faster, enforce unique constraints, and execute
upserts 224x faster—all while maintaining columnstore compression and analytics performance.
Indexes are a fundamental part of database performance optimization![]() , they enable queries to
quickly locate and retrieve data without scanning entire tables. B-tree and hash indexes are among PostgreSQL’s
most widely used index types. However, they are designed for different query types:
, they enable queries to
quickly locate and retrieve data without scanning entire tables. B-tree and hash indexes are among PostgreSQL’s
most widely used index types. However, they are designed for different query types:
B-tree indexes
 : keep data sorted in a hierarchical structure ideal for queries that involve
range (>, <, BETWEEN) and equality (=) lookups. A B-tree index enables you to check unique constraints or for
range-based filtering. You quickly retrieve and filter the relevant rows without scanning all the data.
: keep data sorted in a hierarchical structure ideal for queries that involve
range (>, <, BETWEEN) and equality (=) lookups. A B-tree index enables you to check unique constraints or for
range-based filtering. You quickly retrieve and filter the relevant rows without scanning all the data.When a query searches for a specific value or a range of values in an indexed column, the B-tree structure enables the database to quickly traverse the tree and find the relevant records in logarithmic time (
O(log n)), significantly improving performance compared to a full table scan.Hash indexes
: designed for exact-match lookups (=) and use a hashing function to map values to
unique disk locations. When searching for a specific ID, a hash index allows direct access to the data with
minimal overhead, and provides the fastest resultsWhen a query searches for a single value, such as searching for transaction by transaction ID, hash indexes can be even faster than B-tree indexes as they don’t require tree traversal and have an amortized constant (
O(1)) lookup. Hash indexes don’t support range queries, they are ideal specifically for cases with frequently queried, unique keys.
The performance advantage from these indexing methods comes from optimized data structures designed for efficient key searching. This results in fewer disk page reads, which in turn reduces I/O spikes when locating specific data points or enforcing uniqueness.
PostgreSQL offers multiple index types![]() . For example, the default B-tree, hash, GIN, and BRIN,
all implemented as Index Access Methods (IAMs). PostgreSQL supplies the table access method (TAM)
. For example, the default B-tree, hash, GIN, and BRIN,
all implemented as Index Access Methods (IAMs). PostgreSQL supplies the table access method (TAM)![]() interface for table storage.
interface for table storage.
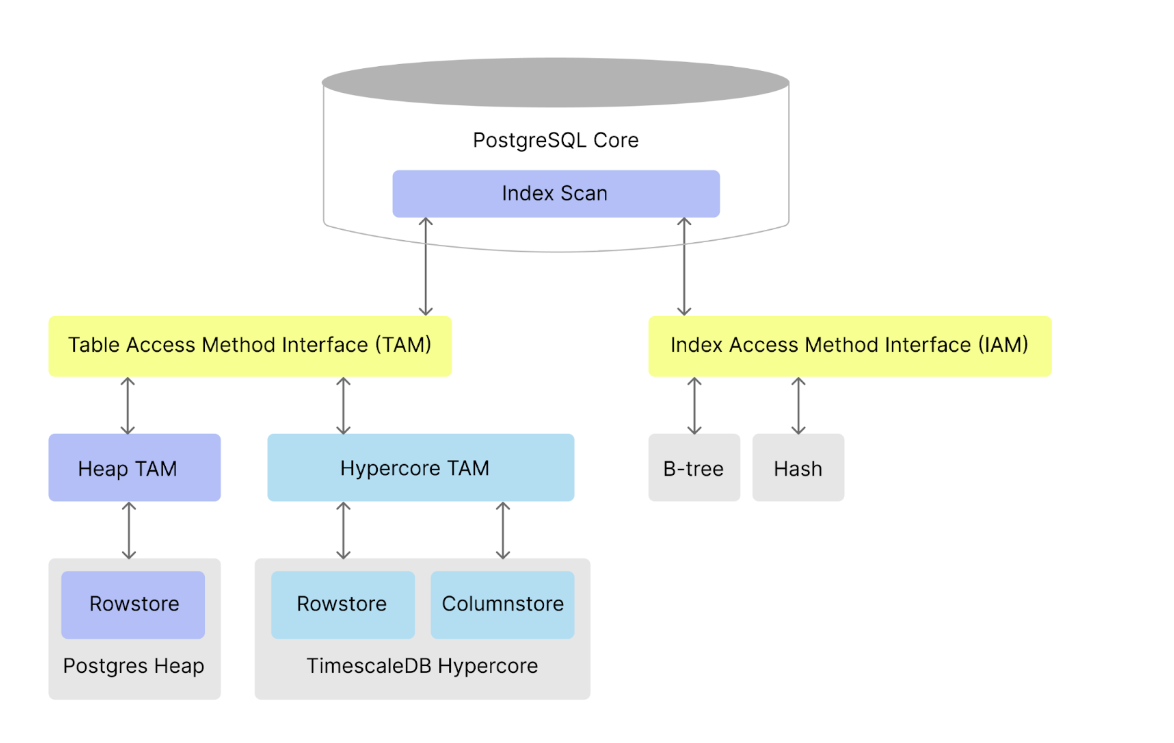
By default, TimescaleDB stores data in the rowstore in standard PostgreSQL row-oriented tables, using the default heap
TAM. To make the heap TAM work with the columnstore, TimescaleDB integrates PostgreSQL TOAST![]() to store
columnar data as compressed arrays. However, querying columnized data returns compressed, opaque data. To support
normal queries, TimescaleDB adds the
to store
columnar data as compressed arrays. However, querying columnized data returns compressed, opaque data. To support
normal queries, TimescaleDB adds the DecompressChunk scan node to the PostgreSQL query plan in order to decompress data
on-the-fly. However, the heap TAM only indexes the compressed values, not the original data.
Hypercore TAM handles decompression behind the scenes. This enables PostgreSQL to use standard interfaces for indexing, to collect statistics, enforce constraints and lock tuples by reference. This also allows PostgreSQL’s built-in scan nodes, such as sequential and index scans, to operate on the columnstore. Custom scan nodes are used for analytical query performance optimizations, including vectorized filtering and aggregation.
Hypercore TAM supports B-tree and hash indexes, making point lookups, upserts, and unique constraint enforcement more efficient on the columnstore. Our benchmarks demonstrate substantial performance improvements:
- 1,185x faster point lookup queries to retrieve a single record.
- 224.3x faster inserts when checking unique constraints.
- 2.6x faster upserts.
- 4.5x faster range queries.
Adding B-tree and hash indexes to compressed data enables dramatically faster lookups and inserts, but it comes with a trade-off: increased storage usage due to additional indexing structures.
B-tree and hash indexes are particularly helpful when:
- You need fast lookups on non-
SEGMENTBYkeys. For example, querying specific records by UUID. - Query latency on compressed data is a bottleneck for your application.
- You perform frequent updates to historical data and need efficient uniqueness enforcement.
However, consider the storage trade-off when:
- Your queries already benefit from columnstore min/max indexes or
SEGMENTBYoptimizations. - Your workloads prioritize compression efficiency over lookup speed.
- You primarily run aggregations and range scans, where indexes may not provide meaningful speedups.
To speed up your queries using secondary indexes, you enable hypercore TAM on your columnstore policy:
Create a table with the desired columns and constraints
create table readings (metric_uuid uuid default gen_random_uuid(),created_at timestamptz not null,uploaded_at timestamptz not null,location_id integer references locations (location_id),device_id integer references devices (device_id),temperature float,humidity float) WITH (tsdb.hypertable,tsdb.partition_column='uploaded_at');Enable hypercore TAM for the hypertable
alter table readingsset access method hypercoreset (timescaledb.orderby = 'created_at',timescaledb.segmentby = 'location_id');This enables the columnstore on the table. Hypercore TAM is applied to chunks created after you set the access method. Existing chunks continue to use the default
heap.To return to the
heapTAM, callset access method heap. You can also change the table access method for an existing chunk with a call likeALTER TABLE _timescaledb_internal._hyper_1_1_chunk SET ACCESS METHOD hypercore;Move chunks from rowstore to columnstore as they age
CALL add_columnstore_policy(readings,interval '1 day',hypercore_use_access_method => true);
Hypercore TAM is now active on all columnstore chunks in the hypertable.
Once you have enabled hypercore TAM in your policy, the indexes are rebuilt when the table chunks are converted from the rowstore to the columnstore. When you query data, these indexes are used by the PostgreSQL query planner over the rowstore and columnstore.
You add hash and B-tree indexes to a hypertable the same way as a regular PostgreSQL table:
- Hash indexCREATE INDEX readings_metric_uuid_hash_idx ON readings USING hash (metric_uuid);
- B-tree indexCREATE UNIQUE INDEX readings_metric_uuid_metric_uuid_uploaded_at_idxON readings (metric_uuid, uploaded_at);
If you have existing chunks that have not been updated to use the hypercore TAM, to use B-tree and hash indexes, you
change the table access method for an existing chunk with a call like ALTER TABLE _timescaledb_internal._hyper_1_1_chunk SET ACCESS METHOD hypercore;
Indexes are particularly useful for highly selective queries, such as retrieving a unique event by its identifier. For example:
SELECTcreated_at,device_id,temperatureFROM readingsWHERE metric_uuid = 'dd19f5d3-d04b-4afc-a78f-9b231fb29e52';
Without an index, a query scans and filters the entire dataset, leading to slow execution and high I/O usage. Min/max sparse indexes help when with incremental numeric IDs but do not work well for random numeric values or UUIDs.
Set a hash index on metric_uuid to enable a direct lookup. This significantly improves performance by decompressing
only the relevant data segment.
CREATE INDEX readings_metric_uuid_hash_idx ON readings USING hash (metric_uuid);
With a hash index and hypercore TAM enabled, the same SELECT query performs 1,185x faster; hash comes in at 10.9 ms vs. 12,915 ms and B-tree at 12.57.
A common use case in real-time applications is backfilling or updating old data. For example, a sensor fails during a batch upload or gets temporarily disconnected, it resends the data later. To avoid possible duplicate records, you have to check if the data already exists in the database before storing it.
To prevent duplicate entries, you enforce uniqueness using a primary key. Primary constraints are enforced through
unique indexes, making conflict checks fast. Without an index, verifying uniqueness involves scanning and decompressing
potentially large amounts of data. This significantly slows inserts and consuming excessive IOPS![]() . A
. A UNIQUE
constraint on a hypertable must also include the hypertable partition key.
The following UNIQUE uses a B-tree index.
CREATE UNIQUE INDEX readings_metric_uuid_metric_uuid_created_at_idxON readings (metric_uuid, created_at);
Possible strategies for backfilling historic data include:
Insert data when the row does not exist:
An insert statement ensuring no duplicates looks like:
INSERT INTO readings VALUES (...) ON CONFLICT (device_id, created_at) DO NOTHING;Our benchmarks showed this makes inserts 224.3x faster, reducing the execution time from 289,139 ms to 1,289 ms.
Insert missing data or update existing data:
An upsert is a database operation that inserts a new row if it does not already exist, or updates the existing row if a conflict occurs. This enables you to re-ingest new versions of rows instead of performing separate update statements. Without an index, the system needs to scan and decompress data, considerably slowing ingestion speed. With a primary key index, conflicting rows are directly located within the compressed data segment in the columnstore.
The following query attempts to insert a new record. If a record for the same
metric_uuidandcreated_atvalues already exists, it updatestemperaturewith the corresponding value from the new record.INSERT INTO readings VALUES (...) ON CONFLICT DO UPDATE SET temperature = EXCLUDED.temperature;Timescale benchmarks showed this makes upserts 2.6x faster, reducing the execution time from 24,805 ms to 9,520 ms.
To regularly report the number of times a device has exceeded a critical temperature, you count the number of times the temperature was exceeded, and group by device ID.
SELECTdevice_id,COUNT(temperature)FROM readingsWHERE temperature > 52.5GROUP BY device_id;
You see something like:
| device_id | count |
|---|---|
| 68 | 1 |
| 258 | 1 |
| 192 | 1 |
| 276 | 1 |
| 114 | 1 |
| 227 | 1 |
| 153 | 1 |
| 210 | 1 |
| 266 | 1 |
| 165 | 1 |
| 296 | 1 |
| 144 | 1 |
| 93 | 1 |
| 285 | 1 |
| 221 | 1 |
| 167 | 1 |
| 14 | 1 |
| 123 | 1 |
| 152 | 1 |
| 206 | 1 |
| 230 | 1 |
| 136 | 1 |
| 256 | 2 |
| 1 | 1 |
To make this query faster, use a partial B-tree index. That is, a B-tree index that only includes rows satisfying a specific WHERE condition. This makes a smaller index that is more efficient for queries that match that condition. For example, to create a partial B-tree index for temperature readings over 52.5:
CREATE INDEX ON readings (temperature) where temperature > 52.5;
Compared with using a sparse min/max index in columnstore, Timescale benchmarks show that the B-tree index query is 4.5x faster.
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.