Timescale Cloud: Performance, Scale, Enterprise
Self-hosted products
MST
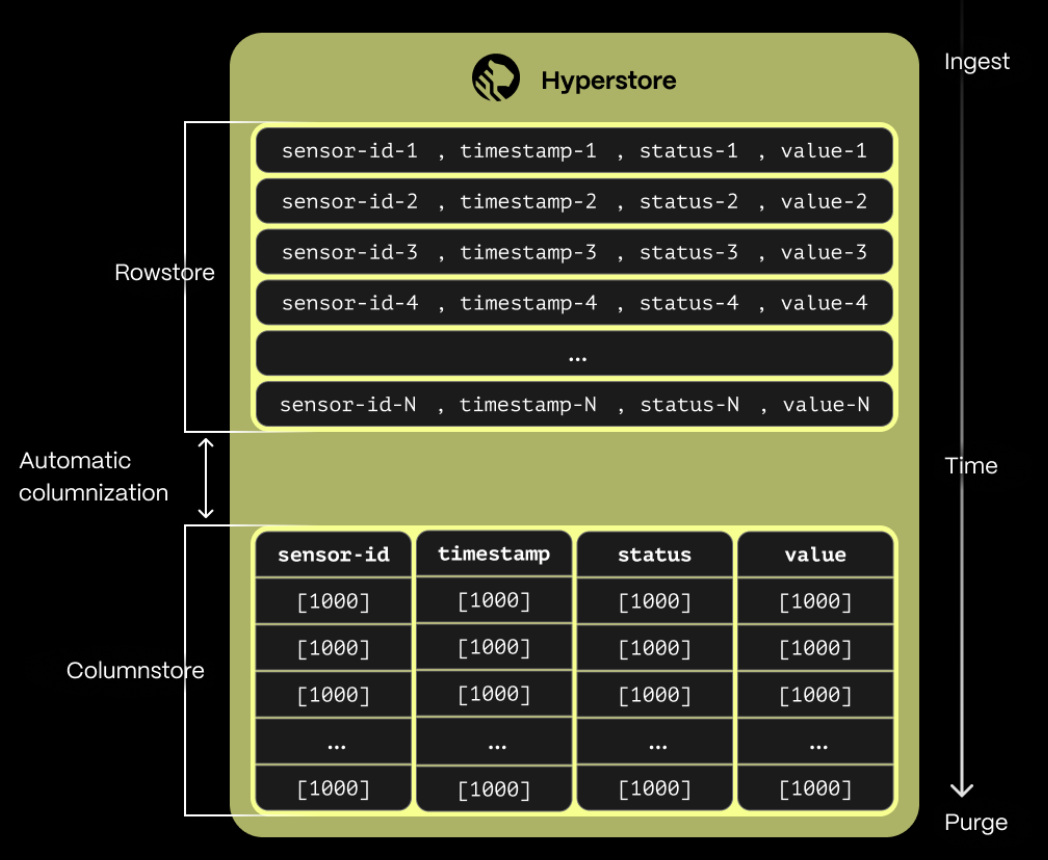
Hypercore is the TimescaleDB hybrid row-columnar storage engine, designed specifically for real-time analytics and powered by time-series data. The advantage of hypercore is its ability to seamlessly switch between row-oriented and column-oriented storage. This flexibility enables Timescale Cloud to deliver the best of both worlds, solving the key challenges in real-time analytics:
- High ingest throughput
- Low-latency ingestion
- Fast query performance
- Efficient handling of data updates and late-arriving data
- Streamlined data management
Hypercore’s hybrid approach combines the benefits of row-oriented and column-oriented formats in each Timescale Cloud service:
Fast ingest with rowstore: new data is initially written to the rowstore, which is optimized for high-speed inserts and updates. This process ensures that real-time applications easily handle rapid streams of incoming data. Mutability—upserts, updates, and deletes happen seamlessly.
Efficient analytics with columnstore: as the data cools and becomes more suited for analytics, it is automatically converted to the columnstore. This columnar format enables fast scanning and aggregation, optimizing performance for analytical workloads while also saving significant storage space.
Faster queries on compressed data in columnstore: in the columnstore conversion, hypertable chunks are compressed by more than 90%, and organized for efficient, large-scale queries. Combined with chunk skipping, this helps you save on storage costs and keeps your queries operating at lightning speed.
Fast modification of compressed data in columnstore: just use SQL to add or modify data in the columnstore. TimescaleDB is optimized for super fast INSERT and UPSERT performance.
Full mutability with transactional semantics: regardless of where data is stored, hypercore provides full ACID support. Like in a vanilla PostgreSQL database, inserts and updates to the rowstore and columnstore are always consistent, and available to queries as soon as they are completed.
Best practice for using hypercore is to:
Enable columnstore
Create a hypertable for your time-series data using CREATE TABLE. For efficient queries on data in the columnstore, remember to
segmentbythe column you will use most often to filter your data. For example:Use
CREATE TABLEfor a hypertableCREATE TABLE crypto_ticks ("time" TIMESTAMPTZ,symbol TEXT,price DOUBLE PRECISION,day_volume NUMERIC) WITH (tsdb.hypertable,tsdb.partition_column='time',tsdb.segmentby='symbol',tsdb.orderby='time DESC');If you are self-hosting TimescaleDB v2.19.3 and below, create a PostgreSQL relational table
 ,
then convert it using create_hypertable. You then enable hypercore with a call
to ALTER TABLE.
,
then convert it using create_hypertable. You then enable hypercore with a call
to ALTER TABLE.Use
ALTER MATERIALIZED VIEWfor a continuous aggregateALTER MATERIALIZED VIEW assets_candlestick_daily set (timescaledb.enable_columnstore = true,timescaledb.segmentby = 'symbol' );
Add a policy to move chunks to the columnstore at a specific time interval
For example, 7 days after the data was added to the table:
CALL add_columnstore_policy('crypto_ticks', after => INTERVAL '7d');View the policies that you set or the policies that already exist
SELECT * FROM timescaledb_information.jobsWHERE proc_name='policy_compression';
You can also convert_to_columnstore and convert_to_rowstore manually for more fine-grained control over your data.
Chunks in the columnstore have the following limitations:
ROW LEVEL SECURITYis not supported on chunks in the columnstore.
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.