Timescale Cloud supercharges your real-time analytics by letting you run complex queries continuously, with near-zero latency. Under the hood, this is achieved by using hypertables - PostgreSQL tables that automatically partition your time-series data by time and optionally by space. When you run a query, Timescale Cloud identifies the correct partition and runs the query on it, instead of going through the entire table.
Hypertables offer a range of other features, such as skipping partitions or running hyperfunctions, that boost the performance of your analytical queries even more.
To top it all, there is no added complexity - you interact with hypertables in the same way as you would with regular PostgreSQL tables. All the optimization magic happens behind the scenes.

Note
Inheritance is not supported for hypertables and may lead to unexpected behavior.
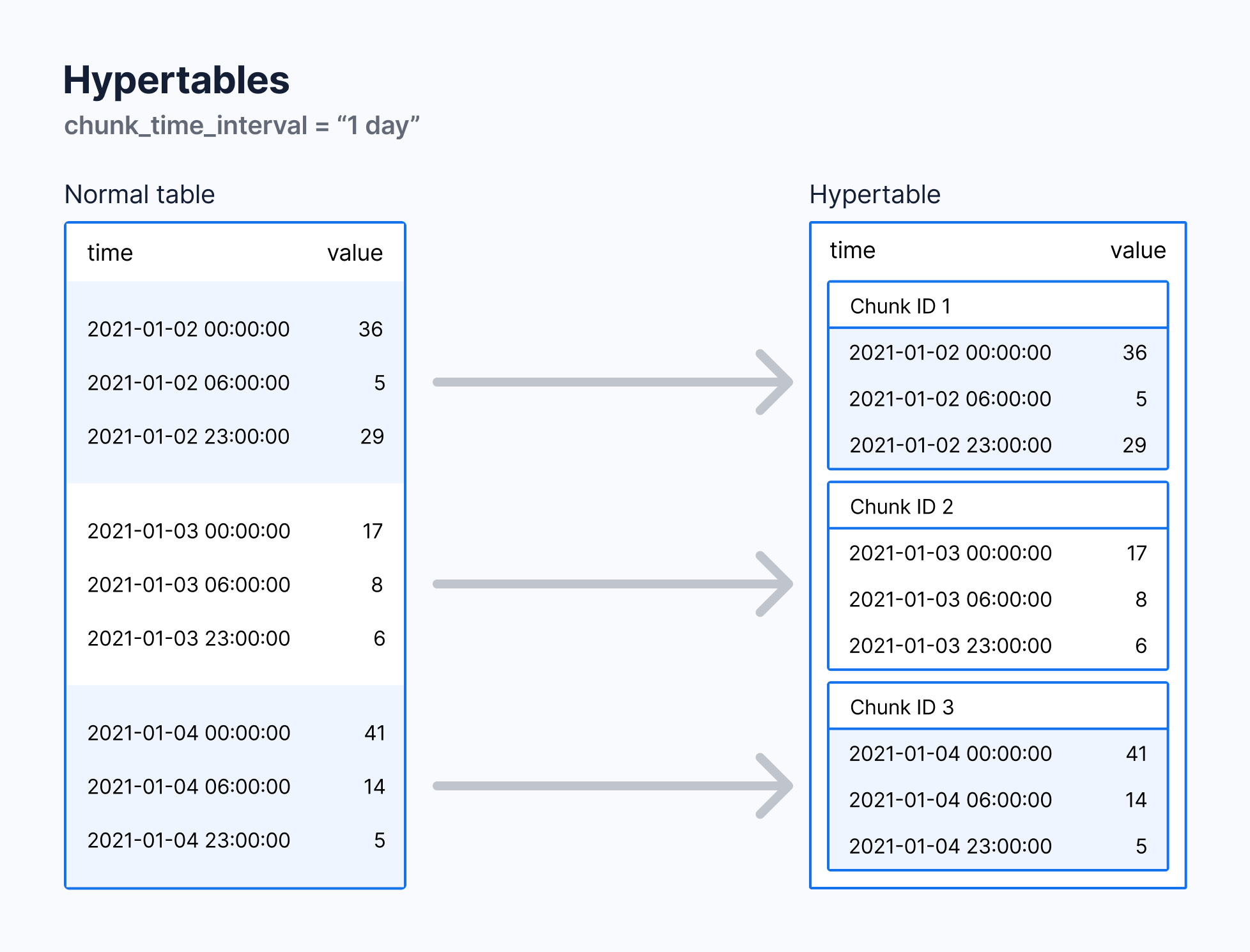
Each hypertable is partitioned into child tables called chunks. Each chunk is assigned a range of time, and only contains data from that range. If the hypertable is also partitioned by space, each chunk is also assigned a subset of the space values.
Note
When a chunk is created then its creation time is stored in the catalog metadata. This chunk creation time should not be confused with the partition ranges for the data that the chunk contains. Certain functionality can use this chunk creation time metadata in cases where it makes sense.
Each chunk of a hypertable only holds data from a specific time range. When you insert data from a time range that doesn't yet have a chunk, Timescale Cloud automatically creates a chunk to store it.
By default, each chunk covers 7 days. You can change this to better suit your
needs. For example, if you set chunk_time_interval to 1 day, each chunk stores
data from the same day. Data from different days is stored in different chunks.
Note
Timescale Cloud divides time into potential chunk ranges, based on the chunk_time_interval. If data exists for a potential chunk range, that chunk is created.
In practice, this means that the start time of your earliest chunk doesn't necessarily equal the earliest timestamp in your hypertable. Instead, there might be a time gap between the start time and the earliest timestamp. This doesn't affect your usual interactions with your hypertable, but might affect the number of chunks you see when inspecting it.
Chunk size affects insert and query performance. You want a chunk small enough to fit into memory so you can insert and query recent data without reading from disk. However, having too many small and sparsely filled chunks can affect query planning time and compression.
Best practice is to set chunk_time_interval so that prior to processing, one chunk of data
takes up 25% of main memory, including the indexes from each active hypertable.
For example, if you write approximately 2 GB of data per day to a database with 64 GB of
memory, set chunk_time_interval to 1 week. If you write approximately 10 GB of data per day
on the same machine, set the time interval to 1 day.
Note
If you use expensive index types, such as some PostGIS geospatial indexes, take
care to check the total size of the chunk and its index. You can do so using the
chunks_detailed_size function.
For a detailed analysis of how to optimize your chunk sizes, see the
blog post on chunk time intervals![]() . To learn how
to view and set your chunk time intervals, see the section on
changing hypertable chunk intervals.
. To learn how
to view and set your chunk time intervals, see the section on
changing hypertable chunk intervals.
By default, indexes are automatically created when you create a hypertable. You
can prevent index creation by setting the create_default_indexes option to
false.
The default indexes are:
- On all hypertables, an index on time, descending
- On hypertables with space partitions, an index on the space parameter and time
Hypertables have some restrictions on unique constraints and indexes. If you want a unique index on a hypertable, it must include all the partitioning columns for the table. To learn more, see the section on creating unique indexes on a hypertable.
You can use the PostgreSQL ANALYZE command to query all chunks in your
hypertable. The statistics collected by the ANALYZE command are used by the
PostgreSQL planner to create the best query plan. For more information about the
ANALYZE command, see the PostgreSQL documentation![]() .
.
- Create a hypertable
- Read about the benefits and architecture of hypertables
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.