Timescale Cloud: Scale, Enterprise
Self-hosted products
MST
Timescale's tiered storage architecture includes a high-performance storage tier and a low-cost object storage tier:
You use high-performance storage to store and query frequently accessed data.
You use low-cost object storage to cut costs by migrating rarely used data from the high-performance storage. After you enable tiered storage, you then either create automated tiering policies or manually tier and untier data.
You can query the data on the object storage tier, but you cannot modify it. Make sure that you are not tiering data that needs to be actively modified.
Timescale charges only for the storage that your data occupies in S3 in the Apache Parquet format, regardless of whether it was compressed in Timescale Cloud before tiering. There are no additional expenses, such as data transfer or compute.
By default, Timescale Cloud stores your service data in the standard high-performance storage. This storage tier comes in the standard and enhanced types. Enhanced storage is available under the Enterprise pricing plan only.
This storage type gives you up to 16 TB of storage and is available under all pricing plans. You change the IOPS value to better suit your needs in Timescale Console:
In Timescale Console
 , select your service, then click
, select your service, then click Operations>Compute and storageBy default, the type of high-performance storage is set to
Standard.Select the IOPS value in the
I/O boostdropdown- Under the Performance pricing plan, IOPS is set to 3,000 - 5,000 autoscale and cannot be changed.
- Under the Scale and Enterprise pricing plans, IOPS is set to 5,000 - 8,000 autoscale and can be upgraded to 16,000 IOPS.
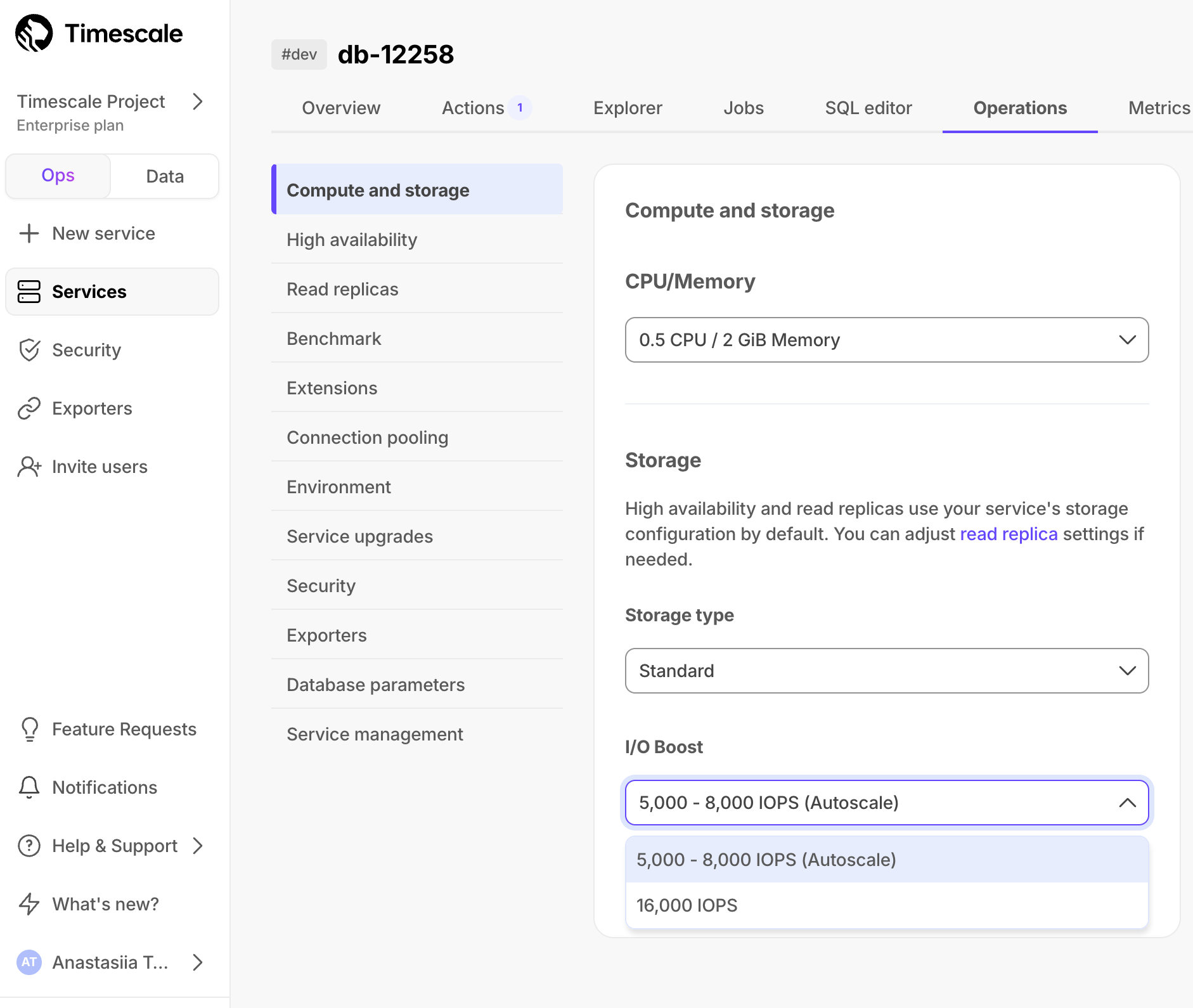
Click
Apply
This storage type gives you up to 64 TB and 32,000 IOPS, and is available under the Enterprise pricing plan. To get enhanced storage:
In Timescale Console
, select your service, then click Operations>Compute and storageSelect
Enhancedin theStorage typedropdown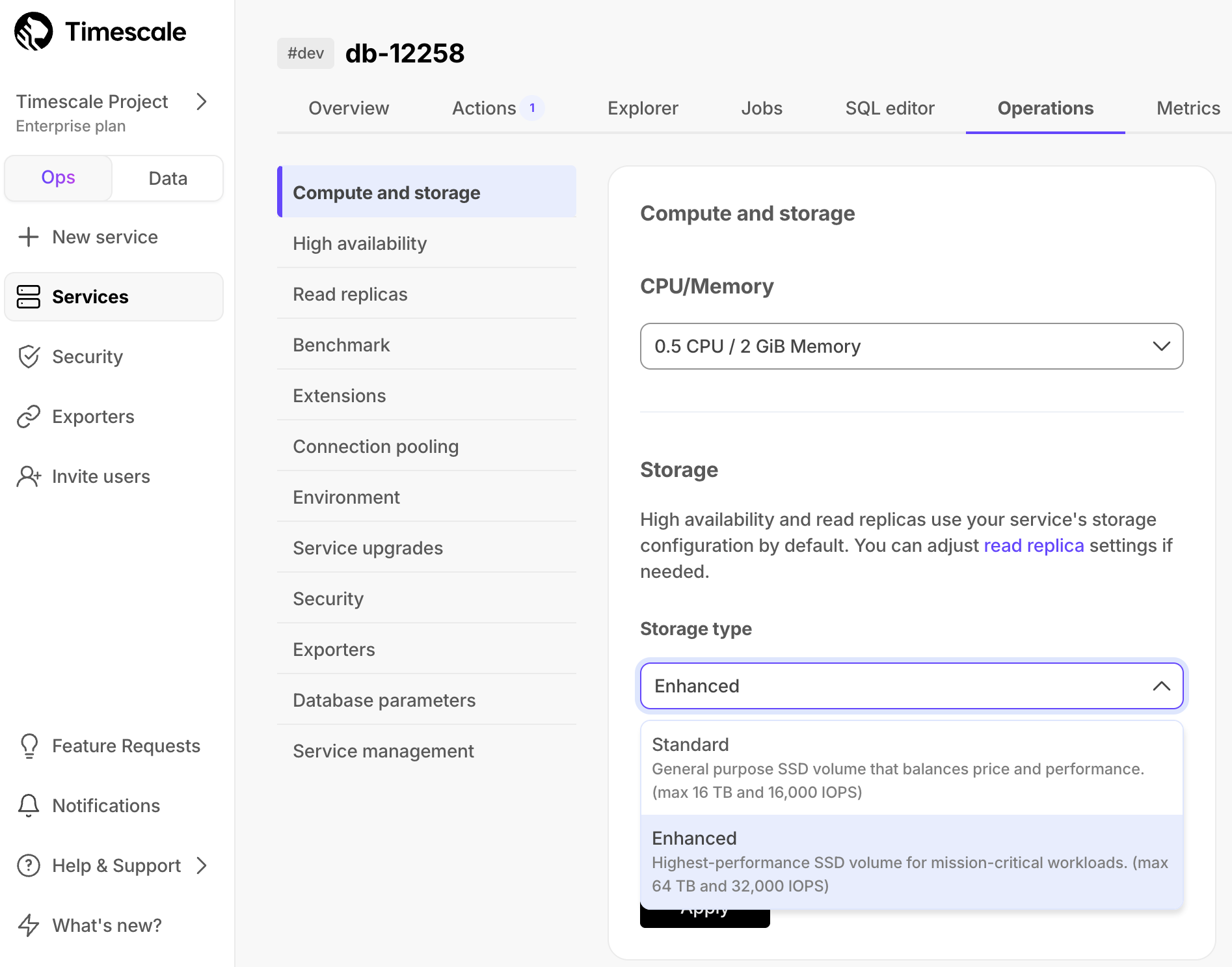

Note
The enhanced storage is currently not available in
sa-east-1.Select the IOPS value in the
I/O boostdropdownSelect between 8,000, 16,000, 24,000, and 32,0000 IOPS. The value that you can apply depends on the number of CPUs in your service. Timescale Console notifies you if your selected IOPS requires increasing the number of CPUs. To increase IOPS to 64,000, click
Contact usand we will be in touch to confirm the details.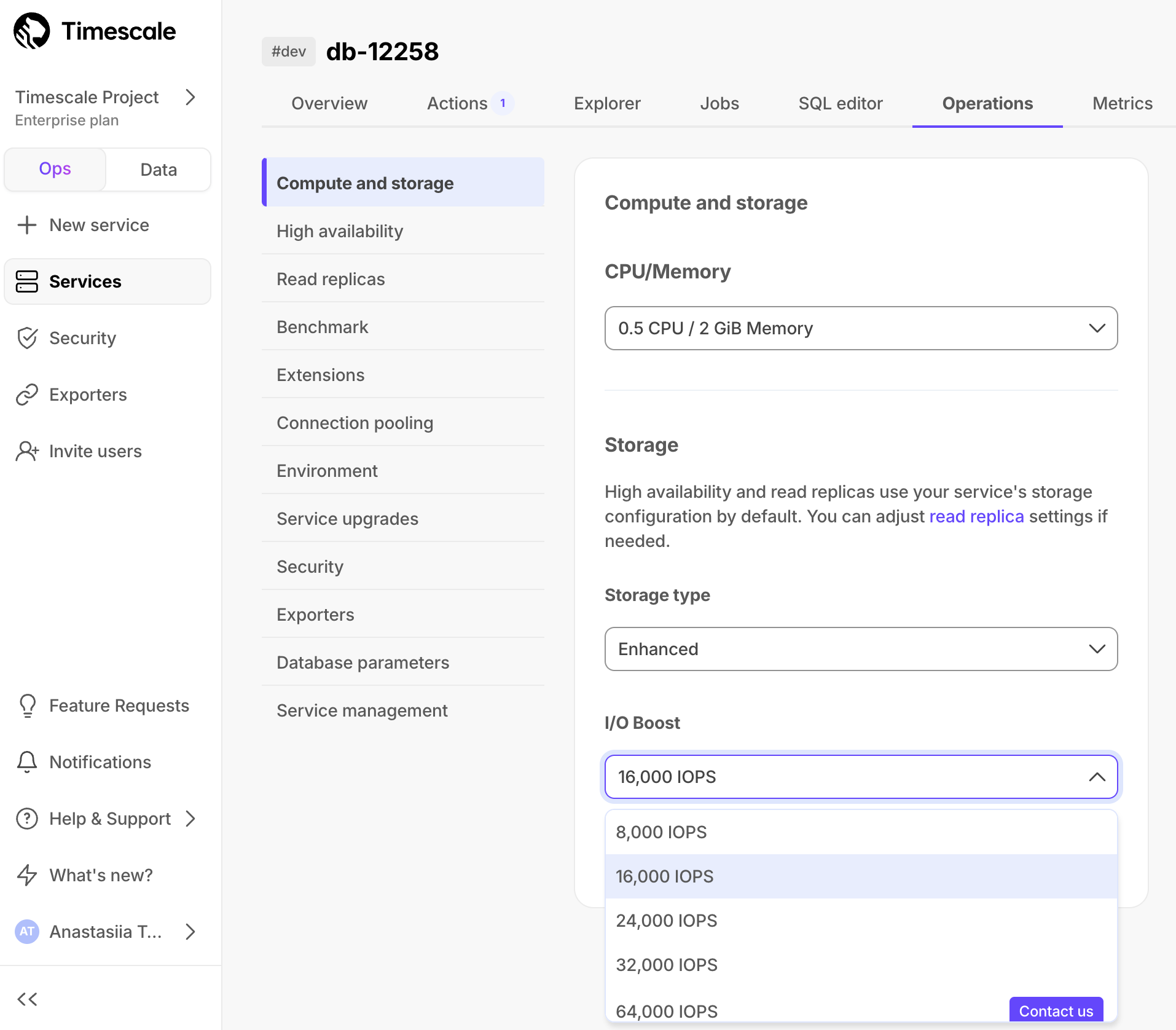
Click
Apply
You change from enhanced storage to standard in the same way. If you are using over 16 TB of enhanced storage, changing back to standard is not available until you shrink your data to be under 16 TB. You can make changes to the storage type and I/O boost settings without any downtime. Wait at least 6 hours to attempt another change.
You enable the low-cost object storage tier in Timescale Console and then tier the data with policies or manually.
You enable tiered storage from the Overview tab in Timescale Console.
In [Timescale Console][portal-ops-mode], select the service to modify
In the
Overviewsection, clickExplorer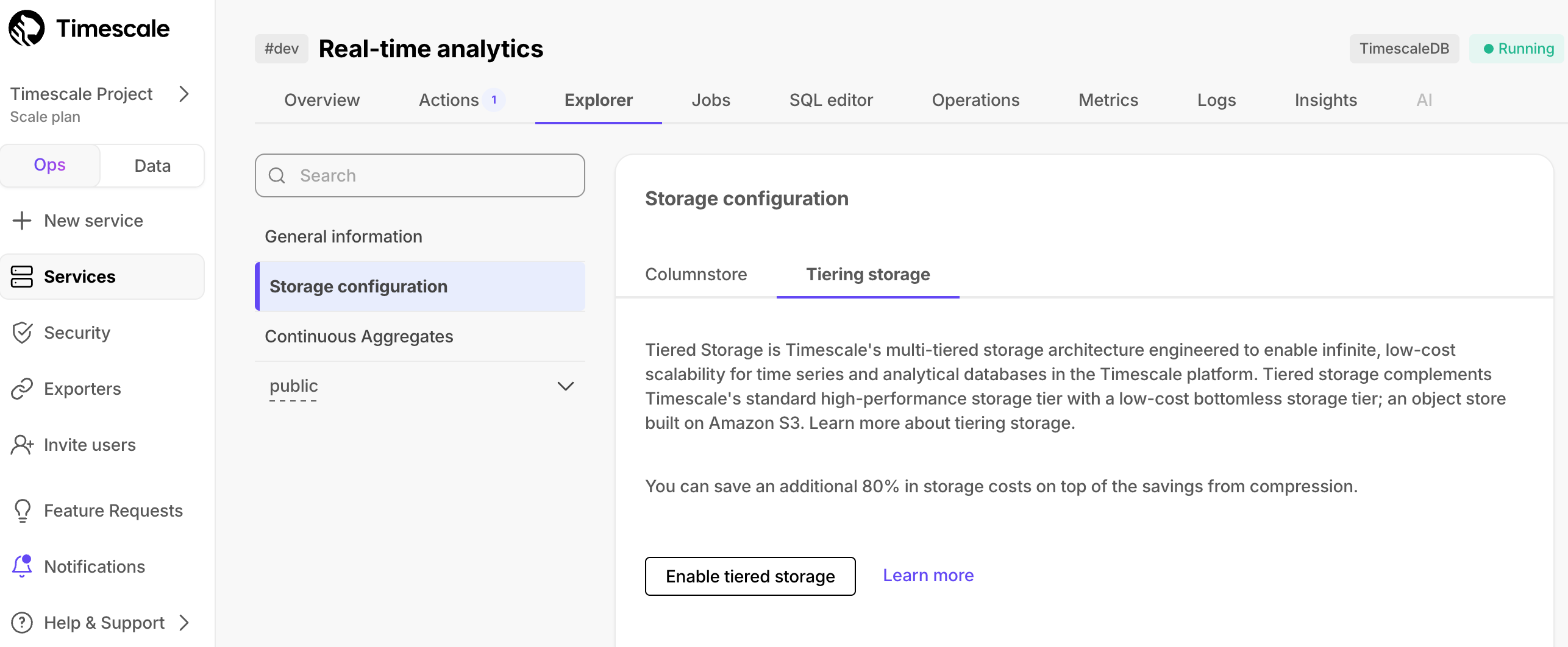
In
Explorer, clickStorage configuration>Tiering storage, then clickEnable tiered storageOnce enabled, you can proceed to tier data manually or set up tiering policies. When tiered storage is enabled, you see the amount of data in the tiered object storage.
Note
Data tiering is available in Scale and Enterprise pricing plans only.
A tiering policy automatically moves any chunks that only contain data
older than the move_after threshold to the object storage tier. This works similarly to a
data retention policy, but chunks are moved rather than deleted.
A tiering policy schedules a job that runs periodically to asynchronously migrate eligible chunks to object storage. Chunks are considered tiered once they appear in the timescaledb_osm.tiered_chunks view.
You can add tiering policies to hypertables, including continuous aggregates. To manage tiering policies, connect to your service and run the queries below in the data mode, the SQL editor, or using psql.
To add a tiering policy, call add_tiering_policy:
SELECT add_tiering_policy(hypertable REGCLASS, move_after INTERVAL, if_not_exists BOOL = false);
For example, to tier chunks that are more than three days old in the example hypertable:
SELECT add_tiering_policy('example', INTERVAL '3 days');
By default, a tiering policy runs hourly on your database. To change this interval, call alter_job.
To remove an existing tiering policy, call remove_tiering_policy:
SELECT remove_tiering_policy(hypertable REGCLASS, if_exists BOOL = false);
For example, to remove the tiering policy from the example hypertable:
SELECT remove_tiering_policy('example');
If you remove a tiering policy, the remaining scheduled chunks are not tiered. However, chunks in tiered storage are not untiered. You untier chunks manually to local storage.
If tiering policies do not meet your current needs, you can tier and untier chunks manually. To do so, connect to your service and run the queries below in the data mode, the SQL editor, or using psql.
Tiering a chunk is an asynchronous process that schedules the chunk to be tiered. In the following example, you tier chunks older than three days in the example hypertable. You then list the tiered chunks.
Select all chunks in
examplethat are older than three days:SELECT show_chunks('example', older_than => INTERVAL '3 days');This returns a list of chunks. Take a note of the chunk names:
_timescaledb_internal._hyper_1_1_chunk_timescaledb_internal._hyper_1_2_chunkCall
tier_chunkto manually tier each chunk:SELECT tier_chunk('_timescaledb_internal._hyper_1_1_chunk');Repeat for all chunks you want to tier.
Tiering a chunk schedules it for migration to the object storage tier, but the migration won't happen immediately. Chunks are tiered one at a time in order to minimize database resource consumption. A chunk is marked as migrated and deleted from the standard storage only after it has been durably stored in the object storage tier. You can continue to query a chunk during migration.
To see which chunks are tiered into the object storage tier, use the
tiered_chunksinformational view:SELECT * FROM timescaledb_osm.tiered_chunks;
To see which chunks are scheduled for tiering either by policy or by a manual call, but have not yet been tiered, use this view:
SELECT * FROM timescaledb_osm.chunks_queued_for_tiering ;
To update data in a tiered chunk, move it back to the standard high-performance storage tier in Timescale Cloud. Untiering chunks is a synchronous process. Chunks are renamed when the data is untiered.
To untier a chunk, call the untier_chunk stored procedure.
Check which chunks are currently tiered:
SELECT * FROM timescaledb_osm.tiered_chunks ;Sample output:
hypertable_schema | hypertable_name | chunk_name | range_start | range_end-------------------+-----------------+------------------+------------------------+------------------------public | sample | _hyper_1_1_chunk | 2023-02-16 00:00:00+00 | 2023-02-23 00:00:00+00(1 row)Call
untier_chunk:CALL untier_chunk('_hyper_1_1_chunk');See the details of the chunk with
timescaledb_information.chunks:SELECT * FROM timescaledb_information.chunks;Sample output:
-[ RECORD 1 ]----------+-------------------------hypertable_schema | publichypertable_name | samplechunk_schema | _timescaledb_internalchunk_name | _hyper_1_4_chunkprimary_dimension | tsprimary_dimension_type | timestamp with time zonerange_start | 2023-02-16 00:00:00+00range_end | 2020-03-23 00:00:00+00range_start_integer |range_end_integer |is_compressed | fchunk_tablespace |data_nodes |
If you no longer want to use tiered storage for a particular hypertable, drop the associated metadata by calling disable_tiering.
To drop all tiering policies associated with a table, call
remove_tiering_policy.Make sure that there is no tiered data associated with this hypertable:
List the tiered chunks associated with this hypertable:
select * from timescaledb_osm.tiered_chunksIf you have any tiered chunks, either untier this data, or drop these chunks from tiered storage.
Use
disable_tieringto drop all tiering-related metadata for the hypertable:select disable_tiering('my_hypertable_name');Verify that tiering has been disabled by listing the hypertables that have tiering enabled:
select * from timescaledb_osm.tiered_hypertables;
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.