Timescale Cloud: Performance, Scale, Enterprise
Self-hosted products
MST
Energy providers understand that customers tend to lose patience when there is not enough power for them to complete day-to-day activities. Task one is keeping the lights on. If you are transitioning to renewable energy, it helps to know when you need to produce energy so you can choose a suitable energy source.
Real-time analytics refers to the process of collecting, analyzing, and interpreting data instantly as it is generated. This approach enables you to track and monitor activity, make the decisions based on real-time insights on data stored in a Timescale Cloud service and keep those lights on.
Grafana![]() is a popular data visualization tool that enables you to create customizable dashboards
and effectively monitor your systems and applications.
is a popular data visualization tool that enables you to create customizable dashboards
and effectively monitor your systems and applications.
This page shows you how to integrate Grafana with a Timescale Cloud service and make insights based on visualization of data optimized for size and speed in the columnstore.
To follow the steps on this page:
Create a target Timescale Cloud service with time-series and analytics enabled.
You need your connection details. This procedure also works for self-hosted TimescaleDB.
- Install and run self-managed Grafana
 , or sign up for Grafana Cloud.
, or sign up for Grafana Cloud.
Time-series data represents the way a system, process, or behavior changes over time. Hypertables enable TimescaleDB to work efficiently with time-series data. Hypertables are PostgreSQL tables that automatically partition your time-series data by time. Each hypertable is made up of child tables called chunks. Each chunk is assigned a range of time, and only contains data from that range. When you run a query, TimescaleDB identifies the correct chunk and runs the query on it, instead of going through the entire table.
Hypercore is the Timescale hybrid row-columnar storage engine used by hypertables. Traditional databases force a trade-off between fast inserts (row-based storage) and efficient analytics (columnar storage). Hypercore eliminates this trade-off, allowing real-time analytics without sacrificing transactional capabilities.
Hypercore dynamically stores data in the most efficient format for its lifecycle:
- Row-based storage for recent data: the most recent chunk (and possibly more) is always stored in the rowstore, ensuring fast inserts, updates, and low-latency single record queries. Additionally, row-based storage is used as a writethrough for inserts and updates to columnar storage.
- Columnar storage for analytical performance: chunks are automatically compressed into the columnstore, optimizing storage efficiency and accelerating analytical queries.
Unlike traditional columnar databases, hypercore allows data to be inserted or modified at any stage, making it a flexible solution for both high-ingest transactional workloads and real-time analytics—within a single database.
Because TimescaleDB is 100% PostgreSQL, you can use all the standard PostgreSQL tables, indexes, stored procedures, and other objects alongside your hypertables. This makes creating and working with hypertables similar to standard PostgreSQL.
Import time-series data into a hypertable
Unzip
to a<local folder>.This test dataset contains energy consumption data.
To import up to 100GB of data directly from your current PostgreSQL based database, migrate with downtime using native PostgreSQL tooling. To seamlessly import 100GB-10TB+ of data, use the live migration tooling supplied by Timescale. To add data from non-PostgreSQL data sources, see Import and ingest data.
In Terminal, navigate to
<local folder>and update the following string with your connection details to connect to your service.psql -d "postgres://<username>:<password>@<host>:<port>/<database-name>?sslmode=require"Create an optimized hypertable for your time-series data:
Create a hypertable with hypercore enabled by default for your time-series data using CREATE TABLE. For efficient queries on data in the columnstore, remember to
segmentbythe column you will use most often to filter your data.In your sql client, run the following command:
CREATE TABLE "metrics"(created timestamp with time zone default now() not null,type_id integer not null,value double precision not null) WITH (tsdb.hypertable,tsdb.partition_column='created',tsdb.segmentby = 'type_id',tsdb.orderby = 'created DESC');If you are self-hosting TimescaleDB v2.19.3 and below, create a PostgreSQL relational table
,
then convert it using create_hypertable. You then enable hypercore with a call
to ALTER TABLE.
Upload the dataset to your service
\COPY metrics FROM metrics.csv CSV;
Have a quick look at your data
You query hypertables in exactly the same way as you would a relational PostgreSQL table. Use one of the following SQL editors to run a query and see the data you uploaded:
- Data mode: write queries, visualize data, and share your results in Timescale Console for all your Timescale Cloud services.
- SQL editor: write, fix, and organize SQL faster and more accurately in Timescale Console for a Timescale Cloud service.
- psql: easily run queries on your Timescale Cloud services or self-hosted TimescaleDB deployment from Terminal.
SELECT time_bucket('1 day', created, 'Europe/Berlin') AS "time",round((last(value, created) - first(value, created)) * 100.) / 100. AS valueFROM metricsWHERE type_id = 5GROUP BY 1;On this amount of data, this query on data in the rowstore takes about 3.6 seconds. You see something like:
Time value 2023-05-29 22:00:00+00 23.1 2023-05-28 22:00:00+00 19.5 2023-05-30 22:00:00+00 25 2023-05-31 22:00:00+00 8.1 - Data mode: write queries, visualize data, and share your results in Timescale Console
When Timescale Cloud converts a chunk to the columnstore, TimescaleDB automatically creates a different schema for your
data. TimescaleDB creates and uses custom indexes to incorporate the segmentby and orderby parameters when
you write to and read from the columstore.
To increase the speed of your analytical queries by a factor of 10 and reduce storage costs by up to 90%, convert data to the columnstore:
Connect to your Timescale Cloud service
In Timescale Console
open an SQL editor. The in-Console editors display the query speed.
You can also connect to your service using psql.Add a policy to convert chunks to the columnstore at a specific time interval
For example, 60 days after the data was added to the table:
CALL add_columnstore_policy('metrics', INTERVAL '8 days');Faster analytical queries on data in the columnstore
Now run the analytical query again:
SELECT time_bucket('1 day', created, 'Europe/Berlin') AS "time",round((last(value, created) - first(value, created)) * 100.) / 100. AS valueFROM metricsWHERE type_id = 5GROUP BY 1;On this amount of data, this analytical query on data in the columnstore takes about 250ms.
Just to hit this one home, by converting cooling data to the columnstore, you have increased the speed of your analytical queries by a factor of 10, and reduced storage by up to 90%.
Aggregation is a way of combining data to get insights from it. Average, sum, and count are all examples of simple aggregates. However, with large amounts of data aggregation slows things down, quickly. Continuous aggregates are a kind of hypertable that is refreshed automatically in the background as new data is added, or old data is modified. Changes to your dataset are tracked, and the hypertable behind the continuous aggregate is automatically updated in the background.
By default, querying continuous aggregates provides you with real-time data. Pre-aggregated data from the materialized view is combined with recent data that hasn't been aggregated yet. This gives you up-to-date results on every query.
You create continuous aggregates on uncompressed data in high-performance storage. They continue to work on data in the columnstore and rarely accessed data in tiered storage. You can even create continuous aggregates on top of your continuous aggregates.
Monitor energy consumption on a day-to-day basis
Create a continuous aggregate
kwh_day_by_dayfor energy consumption:CREATE MATERIALIZED VIEW kwh_day_by_day(time, value)with (timescaledb.continuous) asSELECT time_bucket('1 day', created, 'Europe/Berlin') AS "time",round((last(value, created) - first(value, created)) * 100.) / 100. AS valueFROM metricsWHERE type_id = 5GROUP BY 1;Add a refresh policy to keep
kwh_day_by_dayup-to-date:SELECT add_continuous_aggregate_policy('kwh_day_by_day',start_offset => NULL,end_offset => INTERVAL '1 hour',schedule_interval => INTERVAL '1 hour');
Monitor energy consumption on an hourly basis
Create a continuous aggregate
kwh_hour_by_hourfor energy consumption:CREATE MATERIALIZED VIEW kwh_hour_by_hour(time, value)with (timescaledb.continuous) asSELECT time_bucket('01:00:00', metrics.created, 'Europe/Berlin') AS "time",round((last(value, created) - first(value, created)) * 100.) / 100. AS valueFROM metricsWHERE type_id = 5GROUP BY 1;Add a refresh policy to keep the continuous aggregate up-to-date:
SELECT add_continuous_aggregate_policy('kwh_hour_by_hour',start_offset => NULL,end_offset => INTERVAL '1 hour',schedule_interval => INTERVAL '1 hour');
Analyze your data
Now you have made continuous aggregates, it could be a good idea to use them to perform analytics on your data. For example, to see how average energy consumption changes during weekdays over the last year, run the following query:
WITH per_day AS (SELECTtime,valueFROM kwh_day_by_dayWHERE "time" at time zone 'Europe/Berlin' > date_trunc('month', time) - interval '1 year'ORDER BY 1), daily AS (SELECTto_char(time, 'Dy') as day,valueFROM per_day), percentile AS (SELECTday,approx_percentile(0.50, percentile_agg(value)) as valueFROM dailyGROUP BY 1ORDER BY 1)SELECTd.day,d.ordinal,pd.valueFROM unnest(array['Sun', 'Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat']) WITH ORDINALITY AS d(day, ordinal)LEFT JOIN percentile pd ON lower(pd.day) = lower(d.day);You see something like:
day ordinal value Mon 2 23.08078714975423 Sun 1 19.511430831944395 Tue 3 25.003118897837307 Wed 4 8.09300571759772
To visualize the results of your queries, enable Grafana to read the data in your service:
Log in to Grafana
In your browser, log in to either:
- Self-hosted Grafana: at
http://localhost:3000/. The default credentials areadmin,admin. - Grafana Cloud: use the URL and credentials you set when you created your account.
- Self-hosted Grafana: at
Add your service as a data source
Open
Connections>Data sources, then clickAdd new data source.Select
PostgreSQLfrom the list.Configure the connection:
Host URL,Database name,Username, andPasswordConfigure using your connection details.
Host URLis in the format<host>:<port>.TLS/SSL Mode: selectrequire.PostgreSQL options: enableTimescaleDB.Leave the default setting for all other fields.
Click
Save & test.Grafana checks that your details are set correctly.
A Grafana dashboard represents a view into the performance of a system, and each dashboard consists of one or more panels, which represent information about a specific metric related to that system.
To visually monitor the volume of energy consumption over time:
Create the dashboard
On the
Dashboardspage, clickNewand selectNew dashboard.Click
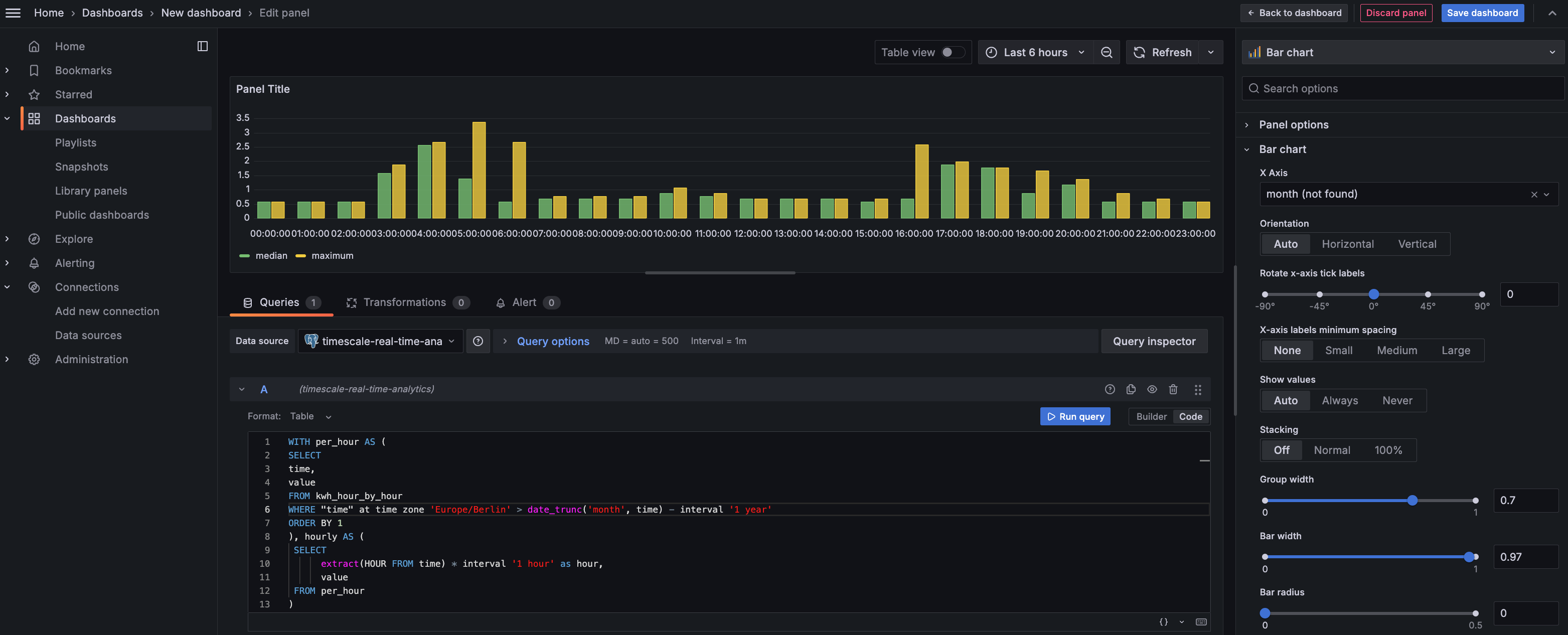
Add visualization, then select the data source that connects to your Timescale Cloud service and theBar chartvisualization.
In the
Queriessection, selectCode, then run the following query based on your continuous aggregate:WITH per_hour AS (SELECTtime,valueFROM kwh_hour_by_hourWHERE "time" at time zone 'Europe/Berlin' > date_trunc('month', time) - interval '1 year'ORDER BY 1), hourly AS (SELECTextract(HOUR FROM time) * interval '1 hour' as hour,valueFROM per_hour)SELECThour,approx_percentile(0.50, percentile_agg(value)) as median,max(value) as maximumFROM hourlyGROUP BY 1ORDER BY 1;This query averages the results for households in a specific time zone by hour and orders them by time. Because you use a continuous aggregate, this data is always correct in real time.
You see that energy consumption is highest in the evening and at breakfast time. You also know that the wind drops off in the evening. This data proves that you need to supply a supplementary power source for peak times, or plan to store energy during the day for peak times.
Click
Save dashboard
You have integrated Grafana with a Timescale Cloud service and made insights based on visualization of your data.
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.