Tiger Cloud: Performance, Scale, Enterprise
Self-hosted products
MST
This document provides detailed step-by-step instructions to migrate data using the dual-write and backfill migration method from a source database which is using TimescaleDB to Tiger Cloud.

Note
In the context of migrations, your existing production database is referred to as the SOURCE database, the Tiger Cloud service that you are migrating your data to is the TARGET.
In detail, the migration process consists of the following steps:
- Set up a target Tiger Cloud service.
- Modify the application to write to a secondary database.
- Migrate schema and relational data from source to target.
- Start the application in dual-write mode.
- Determine the completion point
T. - Backfill time-series data from source to target.
- Enable background jobs (policies) in the target database.
- Validate that all data is present in target database.
- Validate that target database can handle production load.
- Switch application to treat target database as primary (potentially continuing to write into source database, as a backup).

Tip
If you get stuck, you can get help by either opening a support request, or take
your issue to the #migration channel in the community slack![]() ,
where the developers of this migration method are there to help.
,
where the developers of this migration method are there to help.
You can open a support request directly from Tiger Cloud Console![]() ,
or by email to support@tigerdata.com
,
or by email to support@tigerdata.com![]() .
.
If you intend on migrating more than 400 GB, open a support request to ensure that enough disk is pre-provisioned on your Tiger Cloud service.
You can open a support request directly from Tiger Cloud Console![]() ,
or by email to support@tigerdata.com
,
or by email to support@tigerdata.com![]() .
.
How exactly to do this is dependent on the language that your application is written in, and on how exactly your ingestion and application function. In the simplest case, you simply execute two inserts in parallel. In the general case, you must think about how to handle the failure to write to either the source or target database, and what mechanism you want to or can build to recover from such a failure.
Should your time-series data have foreign-key references into a plain table,
you must ensure that your application correctly maintains the foreign key
relations. If the referenced column is a *SERIAL type, the same row inserted
into the source and target may not obtain the same autogenerated id. If this
happens, the data backfilled from the source to the target is internally
inconsistent. In the best case it causes a foreign key violation, in the worst
case, the foreign key constraint is maintained, but the data references the
wrong foreign key. To avoid these issues, best practice is to follow
live migration.
You may also want to execute the same read queries on the source and target database to evaluate the correctness and performance of the results which the queries deliver. Bear in mind that the target database spends a certain amount of time without all data being present, so you should expect that the results are not the same for some period (potentially a number of days).
This section leverages pg_dumpall and pg_dump to migrate the roles and
relational schema that you are using in the source database to the target
database.

Important
The PostgresSQL versions of the source and target databases can be of different versions, as long as the target version is greater than that of the source.
The version of TimescaleDB used in both databases must be exactly the same.
Note
For the sake of convenience, connection strings to the source and target databases are referred to as $SOURCE and $TARGET throughout this guide. This can be set in your shell, for example:
export SOURCE="postgres://<user>:<password>@<source host>:<source port>/<db_name>"export TARGET="postgres://<user>:<password>@<target host>:<target port>/<db_name>"
pg_dumpall -d "$SOURCE" \-l $DB_NAME \--quote-all-identifiers \--roles-only \--file=roles.sql
Tiger Cloud services do not support roles with superuser access. If your SQL dump includes roles that have such permissions, you'll need to modify the file to be compliant with the security model.
You can use the following sed command to remove unsupported statements and
permissions from your roles.sql file:
sed -i -E \-e '/CREATE ROLE "postgres";/d' \-e '/ALTER ROLE "postgres"/d' \-e '/CREATE ROLE "tsdbadmin";/d' \-e '/ALTER ROLE "tsdbadmin"/d' \-e 's/(NO)*SUPERUSER//g' \-e 's/(NO)*REPLICATION//g' \-e 's/(NO)*BYPASSRLS//g' \-e 's/GRANTED BY "[^"]*"//g' \roles.sql
Note
This command works only with the GNU implementation of sed (sometimes referred
to as gsed). For the BSD implementation (the default on macOS), you need to
add an extra argument to change the -i flag to -i ''.
To check the sed version, you can use the command sed --version. While the
GNU version explicitly identifies itself as GNU, the BSD version of sed
generally doesn't provide a straightforward --version flag and simply outputs
an "illegal option" error.
A brief explanation of this script is:
CREATE ROLE "postgres"; andALTER ROLE "postgres": These statements are removed because they require superuser access, which is not supported by Timescale.(NO)SUPERUSER|(NO)REPLICATION|(NO)BYPASSRLS: These are permissions that require superuser access.GRANTED BY role_specification: The GRANTED BY clause can also have permissions that require superuser access and should therefore be removed. Note: according to the TimescaleDB documentation, the GRANTOR in the GRANTED BY clause must be the current user, and this clause mainly serves the purpose of SQL compatibility. Therefore, it's safe to remove it.
pg_dump -d "$SOURCE" \--format=plain \--quote-all-identifiers \--no-tablespaces \--no-owner \--no-privileges \--exclude-table-data='_timescaledb_internal.*' \--file=dump.sql
--exclude-table-data='_timescaledb_internal.*'dumps the structure of the hypertable chunks, but not the data. This creates empty chunks on the target, ready for the backfill process.
--no-tablespacesis required because Tiger Cloud does not support tablespaces other than the default. This is a known limitation.--no-owneris required because Tiger Cloud'stsdbadminuser is not a superuser and cannot assign ownership in all cases. This flag means that everything is owned by the user used to connect to the target, regardless of ownership in the source. This is a known limitation.--no-privilegesis required because thetsdbadminuser for your Tiger Cloud service is not a superuser and cannot assign privileges in all cases. This flag means that privileges assigned to other users must be reassigned in the target database as a manual clean-up task. This is a known limitation.
If the source database has the TimescaleDB extension installed in a schema other than "public" it causes issues on Tiger Cloud. Edit the dump file to remove any references to the non-public schema. The extension must be in the "public" schema on Tiger Cloud. This is a known limitation.
It is very important that the version of the TimescaleDB extension is the same in the source and target databases. This requires upgrading the TimescaleDB extension in the source database before migrating.
You can determine the version of TimescaleDB in the target database with the following command:
psql $TARGET -c "SELECT extversion FROM pg_extension WHERE extname = 'timescaledb';"
To update the TimescaleDB extension in your source database, first ensure that the desired version is installed from your package repository. Then you can upgrade the extension with the following query:
psql $SOURCE -c "ALTER EXTENSION timescaledb UPDATE TO '<version here>';"
For more information and guidance, consult the Upgrade TimescaleDB page.
psql -X -d "$TARGET" \-v ON_ERROR_STOP=1 \--echo-errors \-f roles.sql \-c 'select public.timescaledb_pre_restore();' \-f dump.sql \-f - <<'EOF'begin;select public.timescaledb_post_restore();-- disable all background jobsselect public.alter_job(id::integer, scheduled=>false)from _timescaledb_config.bgw_jobwhere id >= 1000;commit;EOF
Note
Background jobs are turned off to prevent continuous aggregate refresh jobs from updating the continuous aggregate with incomplete/missing data. The continuous aggregates must be manually updated in the required range once the migration is complete.
With the target database set up, your application can now be started in dual-write mode.
After dual-writes have been executing for a while, the target hypertable contains data in three time ranges: missing writes, late-arriving data, and the "consistency" range
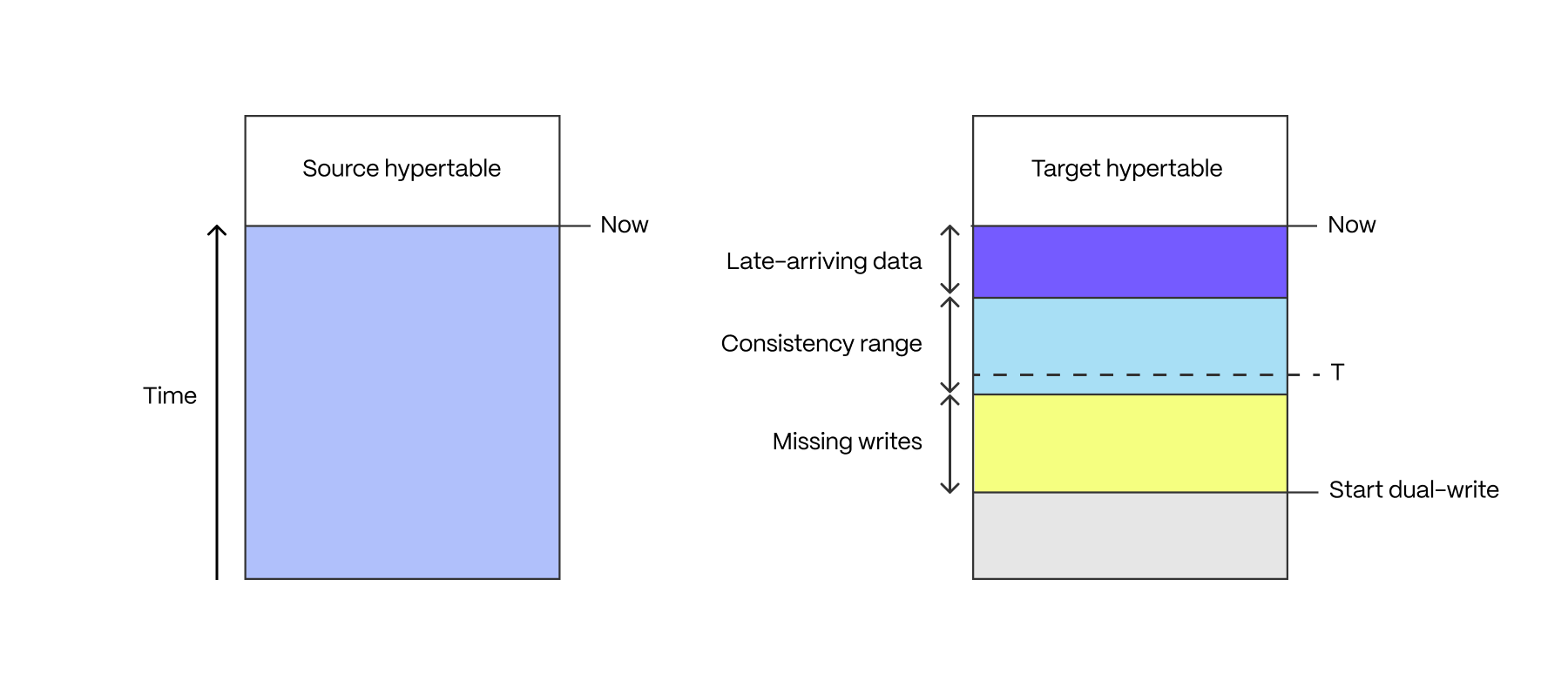
If the application is made up of multiple writers, and these writers did not all simultaneously start writing into the target hypertable, there is a period of time in which not all writes have made it into the target hypertable. This period starts when the first writer begins dual-writing, and ends when the last writer begins dual-writing.
Some applications have late-arriving data: measurements which have a timestamp in the past, but which weren't written yet (for example from devices which had intermittent connectivity issues). The window of late-arriving data is between the present moment, and the maximum lateness.
The consistency range is the range in which there are no missing writes, and in which all data has arrived, that is between the end of the missing writes range and the beginning of the late-arriving data range.
The length of these ranges is defined by the properties of the application, there is no one-size-fits-all way to determine what they are.
The completion point T is an arbitrarily chosen time in the consistency range.
It is the point in time to which data can safely be backfilled, ensuring that
there is no data loss.
The completion point should be expressed as the type of the time column of
the hypertables to be backfilled. For instance, if you're using a TIMESTAMPTZ
time column, then the completion point may be 2023-08-10T12:00:00.00Z. If
you're using a BIGINT column it may be 1695036737000.
If you are using a mix of types for the time columns of your hypertables, you
must determine the completion point for each type individually, and backfill
each set of hypertables with the same type independently from those of other
types.
The simplest way to backfill from TimescaleDB, is to use the timescaledb-backfill backfill tool. It efficiently copies hypertables with the columnstore or compression enabled, and data stored in continuous aggregates from one database to another.
timescaledb-backfill performs best when executed from a machine located close
to the target database. The ideal scenario is an EC2 instance located in the
same region as the Tiger Cloud service. Use a Linux-based distribution on x86_64.
With the instance that will run the timescaledb-backfill ready, log in and download timescaledb-backfill:
wget https://assets.timescale.com/releases/timescaledb-backfill-x86_64-linux.tar.gztar xf timescaledb-backfill-x86_64-linux.tar.gzsudo mv timescaledb-backfill /usr/local/bin/
Running timescaledb-backfill is a four-phase process:
- Stage:
This step prepares metadata about the data to be copied in the target
database. On completion, it outputs the number of chunks to be copied.timescaledb-backfill stage --source $SOURCE --target $TARGET --until <completion point>
- Copy:
This step copies data on a chunk-by-chunk basis from the source to the
target. If it fails or is interrupted, it can safely be resumed. You should
be aware of the
--parallelismparameter, which dictates how many connections are used to copy data. The default is 8, which, depending on the size of your source and target databases, may be too high or too low. You should closely observe the performance of your source database and tune this parameter accordingly.timescaledb-backfill copy --source $SOURCE --target $TARGET - Verify (optional):
This step verifies that the data in the source and target is the same. It
reads all the data on a chunk-by-chunk basis from both the source and target
databases, so may also impact the performance of your source database.timescaledb-backfill verify --source $SOURCE --target $TARGET
- Clean:
This step removes the metadata which was created in the target database by
the
stagecommand.timescaledb-backfill clean --target $TARGET
Before enabling the jobs, verify if any continuous aggregate refresh policies exist.
psql -d $TARGET \-c "select count(*)from _timescaledb_config.bgw_jobwhere proc_name = 'policy_refresh_continuous_aggregate'"
If they do exist, refresh the continuous aggregates before re-enabling the jobs. The timescaledb-backfill tool provides a utility to do this:
timescaledb-backfill refresh-caggs --source $SOURCE --target $TARGET
Once the continuous aggregates are updated, you can re-enable all background jobs:
psql -d $TARGET -f - <<EOFselect public.alter_job(id::integer, scheduled=>true)from _timescaledb_config.bgw_jobwhere id >= 1000;EOF
Note
If the backfill process took long enough for there to be significant retention/compression work to be done, it may be preferable to run the jobs manually to have control over the pacing of the work until it is caught up before re-enabling.
Now that all data has been backfilled, and the application is writing data to both databases, the contents of both databases should be the same. How exactly this should best be validated is dependent on your application.
If you are reading from both databases in parallel for every production query, you could consider adding an application-level validation that both databases are returning the same data.
Another option is to compare the number of rows in the source and target
tables, although this reads all data in the table which may have an impact on
your production workload. timescaledb-backfill's verify subcommand performs
this check.
Another option is to run ANALYZE on both the source and target tables and
then look at the reltuples column of the pg_class table on a chunk-by-chunk
basis. The result is not exact, but doesn't require reading all rows from the
table.
Now that dual-writes have been in place for a while, the target database should be holding up to production write traffic. Now would be the right time to determine if the target database can serve all production traffic (both reads and writes). How exactly this is done is application-specific and up to you to determine.
Once you've validated that all the data is present, and that the target database can handle the production workload, the final step is to switch to the target database as your primary. You may want to continue writing to the source database for a period, until you are certain that the target database is holding up to all production traffic.
Keywords
Found an issue on this page?Report an issue![]() or Edit this page
or Edit this page![]() in GitHub.
in GitHub.