
Warning
Multi-node support is deprecated.
TimescaleDB v2.13 is the last version that includes multi-node support. It supports multi-node installations with PostgreSQL versions 13, 14, and 15. For more information, see Multi-node Deprecation.
If you have a larger petabyte-scale workload, you might need more than one TimescaleDB instance. TimescaleDB multi-node allows you to run and manage a cluster of databases, which can give you faster data ingest, and more responsive and efficient queries for large workloads.

Important
In some cases, your queries could be slower in a multi-node cluster due to the extra network communication between the various nodes. Queries perform the best when the query processing is distributed among the nodes and the result set is small relative to the queried dataset. It is important that you understand multi-node architecture before you begin, and plan your database according to your specific requirements.
Multi-node TimescaleDB allows you to tie several databases together into a logical distributed database to combine the processing power of many physical PostgreSQL instances.
One of the databases exists on an access node and stores metadata about the other databases. The other databases are located on data nodes and hold the actual data. In theory, a PostgreSQL instance can serve as both an access node and a data node at the same time in different databases. However, it is recommended not to have mixed setups, because it can be complicated, and server instances are often provisioned differently depending on the role they serve.
For self-hosted installations, create a server that can act as an access node, then use that access node to create data nodes on other servers.
When you have configured multi-node TimescaleDB, the access node coordinates the placement and access of data chunks on the data nodes. In most cases, it is recommend that you use multidimensional partitioning to distribute data across chunks in both time and space dimensions. The figure in this section shows how an access node (AN) partitions data in the same time interval across multiple data nodes (DN1, DN2, and DN3).
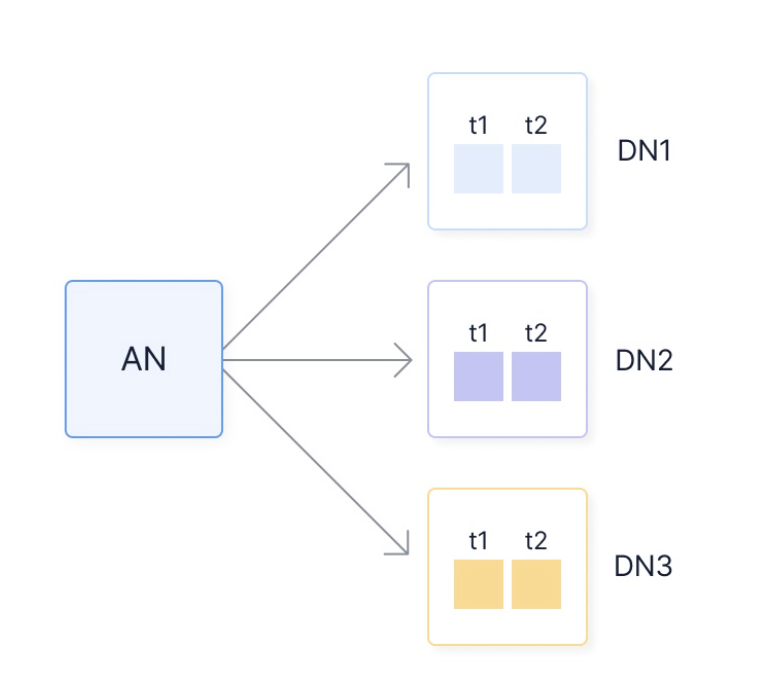
A database user connects to the access node to issue commands and execute queries, similar to how one connects to a regular single node TimescaleDB instance. In most cases, connecting directly to the data nodes is not necessary.
Because TimescaleDB exists as an extension within a specific database, it is possible to have both distributed and non-distributed databases on the same access node. It is also possible to have several distributed databases that use different sets of physical instances as data nodes. In this section, however, it is assumed that you have a single distributed database with a consistent set of data nodes.
If you use a regular table or hypertable on a distributed database, they are not automatically distributed. Regular tables and hypertables continue to work as usual, even when the underlying database is distributed. To enable multi-node capabilities, you need to explicitly create a distributed hypertable on the access node to make use of the data nodes. A distributed hypertable is similar to a regular hypertable, but with the difference that chunks are distributed across data nodes instead of on local storage. By distributing the chunks, the processing power of the data nodes is combined to achieve higher ingest throughput and faster queries. However, the ability to achieve good performance is highly dependent on how the data is partitioned across the data nodes.
To achieve good ingest performance, write the data in batches, with each batch containing data that can be distributed across many data nodes. To achieve good query performance, spread the query across many nodes and have a result set that is small relative to the amount of processed data. To achieve this, it is important to consider an appropriate partitioning method.
Data that is ingested into a distributed hypertable is spread across the data nodes according to the partitioning method you have chosen. Queries that can be sent from the access node to multiple data nodes and processed simultaneously generally run faster than queries that run on a single data node, so it is important to think about what kind of data you have, and the type of queries you want to run.
TimescaleDB multi-node currently supports capabilities that make it best suited
for large-volume time-series workloads that are partitioned on time, and a
space dimension such as location. If you usually run wide queries that
aggregate data across many locations and devices, choose this partitioning
method. For example, a query like this is faster on a database partitioned on
time,location, because it spreads the work across all the data nodes in
parallel:
SELECT time_bucket('1 hour', time) AS hour, location, avg(temperature)FROM conditionsGROUP BY hour, locationORDER BY hour, locationLIMIT 100;
Partitioning on time and a space dimension such as location, is also best if
you need faster insert performance. If you partition only on time, and your
inserts are generally occuring in time order, then you are always writing to one
data node at a time. Partitioning on time and location means your
time-ordered inserts are spread across multiple data nodes, which can lead to
better performance.
If you mostly run deep time queries on a single location, you might see better
performance by partitioning solely on the time dimension, or on a space
dimension other than location. For example, a query like this is faster on a
database partitioned on time only, because the data for a single location is
spread across all the data nodes, rather than being on a single one:
SELECT time_bucket('1 hour', time) AS hour, avg(temperature)FROM conditionsWHERE location = 'office_1'GROUP BY hourORDER BY hourLIMIT 100;
Transactions that occur on distributed hypertables are atomic, just like those on regular hypertables. This means that a distributed transaction that involves multiple data nodes is guaranteed to either succeed on all nodes or on none of them. This guarantee is provided by the two-phase commit protocol, which is used to implement distributed transactions in TimescaleDB.
However, the read consistency of a distributed hypertable is different to a regular hypertable. Because a distributed transaction is a set of individual transactions across multiple nodes, each node can commit its local transaction at a slightly different time due to network transmission delays or other small fluctuations. As a consequence, the access node cannot guarantee a fully consistent snapshot of the data across all data nodes. For example, a distributed read transaction might start when another concurrent write transaction is in its commit phase and has committed on some data nodes but not others. The read transaction can therefore use a snapshot on one node that includes the other transaction's modifications, while the snapshot on another data node might not include them.
If you need stronger read consistency in a distributed transaction, then you can use consistent snapshots across all data nodes. However, this requires a lot of coordination and management, which can negatively effect performance, and it is therefore not implemented by default for distributed hypertables.
If you are using Timescale in a multi-node environment, there are some additional considerations for continuous aggregates.
When you create a continuous aggregate within a multi-node environment, the continuous aggregate should be created on the access node. While it is possible to create a continuous aggregate on data nodes, it interferes with the continuous aggregates on the access node and can cause problems.
When you refresh a continuous aggregate on an access node, it computes a single window to update the time buckets. This could slow down your query if the actual number of rows that were updated is small, but widely spread apart. This is aggravated if the network latency is high if, for example, you have remote data nodes.
Invalidation logs are on kept on the data nodes, which is designed to limit the amount of data that needs to be transferred. However, some statements send invalidations directly to the log, for example, when dropping a chunk or truncate a hypertable. This action could slow down performance, in comparison to a local update. Additionally, if you have infrequent refreshes but a lot of changes to the hypertable, the invalidation logs could get very large, which could cause performance issues. Make sure you are maintaining your invalidation log size to avoid this, for example, by refreshing the continuous aggregate frequently.
For more information about setting up multi-node, see the multi-node section
Keywords
Found an issue on this page?
Report an issue!